국내 인공지능(AI) 리걸테크 분야 대표 기업 인텔리콘연구소(대표 임영익)는 국내 최초로 한국 법률에 특화된 경량화 대형언어모델(sLLM, Smaller Large Language Model)인 '코알라(KOALLA : Korean Adaptive Legal Language AI)' 개발에 성공했다고 28일 밝혔다.
이번에 개발한 '코알라1.0'은 리걸테크의 다양한 응용 서비스에 적용이 되며, 기업이나 로펌의 대용량 문서를 기반으로 하는 생성AI(RAG) 시스템에도 장착이 된다. 따라서 기업의 다양한 환경과 요구에 부응하는 온-프레미스(On-Premise) 또는 설치형(Appliance) 방식의 법률특화 생성AI 도입이 가능해진다.
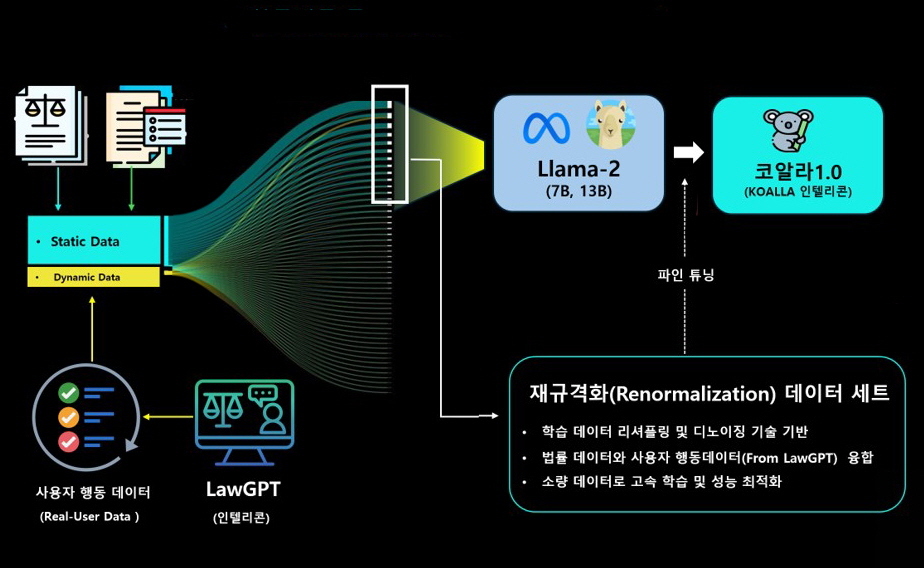
'코알라'는 메타의 Llama-2(7B,13B)를 파인튜닝(Fine-Tuning)해서 개발되었다. 인텔리콘은 코알라의 성능을 높이기 위하여 널리 알려진 DPO(Direct Preference Optimization)같은 기법 외에도 학습 데이터 구성 자체를 최적화하는 데이터 재규격화(Renormalization)기술을 개발하여 추가 학습에 사용하였다.
먼저 수 백만개의 법률, 판례, 상담자료, 주석자료 등을 기반으로 학습 데이터 규격화 작업을 한 후, 성능향상에 도움이 되는 데이터만을 선별하여 재규격화 하였다.
데이터 재규격화 기법은 인텔리콘이 자체로 고안한 특허 기술로 방대한 학습 데이터에서 성능향상에 불필요한 데이터를 제거하는 데이터 디노이징(Data-denoizing)기법과 실제 사용자의 행동 패턴 데이터를 융합하여 리셔플링(Re-shuffling)하는 기술을 포함한다.
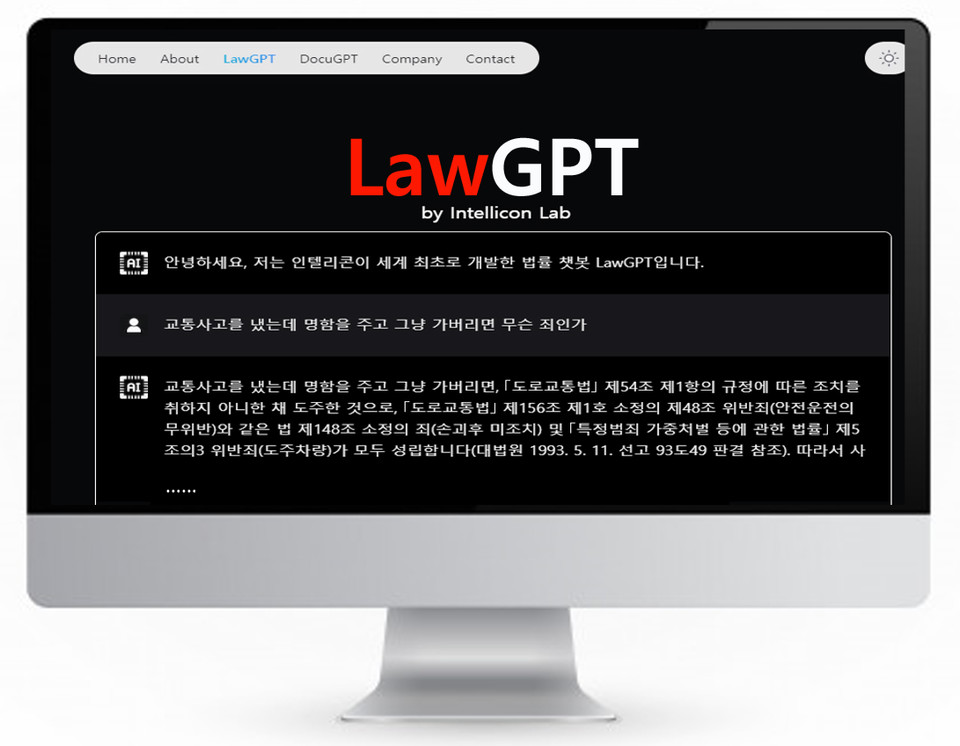
사용자 데이터는 살아 움직이는 데이터(Dynamic Data)로 인텔리콘이 아사아 최초로 지난해 5월에 개발한 법률GPT(LawGPT)와 도큐브레인(DocuBrain)을 통해 얻어진 자료들이다.
GPT같은 거대언어모델(LLM)은 거짓 답변을 만들어 내는 환각현상(Hallucination)때문에 법률, 의료 등에 직접 사용하면 위험하다. 이런 문제를 해결하기 위해 근거기반 생성AI(RAG)가 인기를 모으고 있다.
최근에는 경량화 대형언어모델(sLLM)을 기반으로 수천개에서 수만개의 데이터만으로 파인 튜닝을 하여 독자모델을 완성하는 방향으로 생성AI 생태계가 조성되고 있는 상황이다.
업계는 어떤 질문에도 응답하는 만능 거대언어모델보다는 자신 만의 내부 데이터를 기반으로 정교한 답을 생성하는 RAG방식이나 특화된 언어모델을 선호한다. 미국의 거대언어모델 API를 이용하는 대신에 한국 법률에 특화된 거대언어모델을 직접 적용하는 것은 문서 보안 문제 등을 해결하면서 국내 리걸테크 산업에 큰 변화를 줄 것으로 평가된다.
임영익 대표는 "자체 모델을 개발하면서 깨달은 것이 있습니다. 모델성능의 본질은 모델 자체가 아니라 데이터에 있다는 결론을 내렸습니다"라며, "아무리 모델을 잘 선택해서 다양한 기법을 동원한다고 해도 미국의GPT-4 성능에 근접하는 것은 무리이며 가성비도 좋지 않습니다"라고 말했다.
이어 임 대표는 "인텔리콘은 모델뿐만 아니라 학습 데이터 구조 자체에 좀 더 집중하는 연구를 하면서 데이터 재규격화 기법을 고안하게 되었고, 소량의 데이터로 성능을 극대화할 수 있다는 것을 확인하였습니다"며, "앞으로 다른 모델도 활용하여 코알라2.0 개발 및 고도화를 진행하며, 다양한 코알라를 만든 후 경량모델 블랜딩(Blending) 기술을 적용하여 거대언어모델에 근접시키는 ‘앙상블 브레인’을 개발할 계획입니다” 라고 향후 계획을 밝혔다.