삼성 28나노공정 활용, GPT-2 거대 언어 모델을 400mW전력 소모로 성공적 구동... GPU(엔비디아 A100) 대비 소모전력은 625배, 칩 면적 41배 작은 인공지능 반도체 핵심기술 개발

KAIST(총장 이광형) PIM(Processing In Memory)반도체 연구센터와 인공지능반도체 대학원(원장 유회준. KAIST Graduate School of AI Semiconductor) 유회준 교수 연구팀이 400밀리와트 초저전력을 소모하면서 0.4초 초고속으로 대형언어모델(LLM)을 처리할 수 있는 AI 반도체인 ‘상보형-트랜스포머(Complementary-Transformer)’를 삼성 28나노 공정을 통해 세계 최초로 개발했다.
상보형 트랜스포머는 자연 신경망을 더욱 유사하게 모방한 인공신경망 스파이킹 뉴럴 네트워크(Spiking neural network 이하, SNN)와 심층 인공신경망(이하, DNN)을 선택적으로 사용하여 트랜스포머 기능을 구현한다.
SNN은 뉴로모픽 컴퓨팅의 한 형태로, 뇌의 뉴런이 스파이크라는 시간에 따른 신호를 사용해 정보를 처리하는 방식으로 생물학적 뇌의 작동 방식에 가까워 에너지 효율이 높고, 실시간 처리와 복잡한 시계열 데이터 분석에 적합하다.

연구팀은 그동안 다량의 GPU와 250와트의 전력소모를 통해 구동되는 GPT 등 거대 언어 모델(Large Language Model, LLM)을 4.5mm x 4.5mm의 작은 한 개의 AI 반도체 칩 상에서 초저전력으로 구현하는 것에 성공하였다. 특히 인간 뇌의 동작을 모사하는 뉴로모픽 컴퓨팅(Neuromorphic Computing) 기술, 즉 SNN을 활용하여 트랜스포머 동작을 구현한 것이 특징이다.
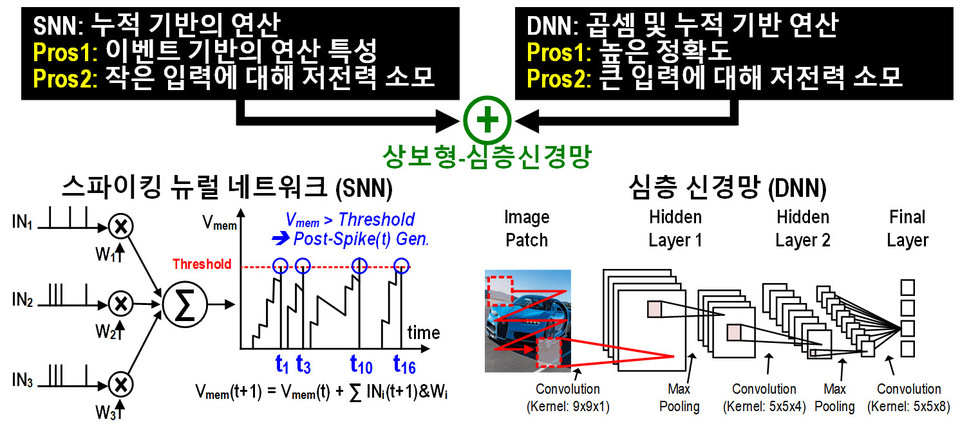
기존 뉴로모픽 컴퓨팅 기술은 합성곱신경망(Convolutional Neural Network, CNN)에 비해 부정확하며 주로 간단한 이미지 분류 작업만 가능하였다. 연구팀은 뉴로모픽 컴퓨팅 기술의 정확도를 CNN과 동일 수준으로 끌어올리고, 단순 이미지 분류를 넘어 다양한 분야에 적용할 수 있는 '상보형-심층신경망 (C-DNN, Complementary-DNN)'을 제안하였다.
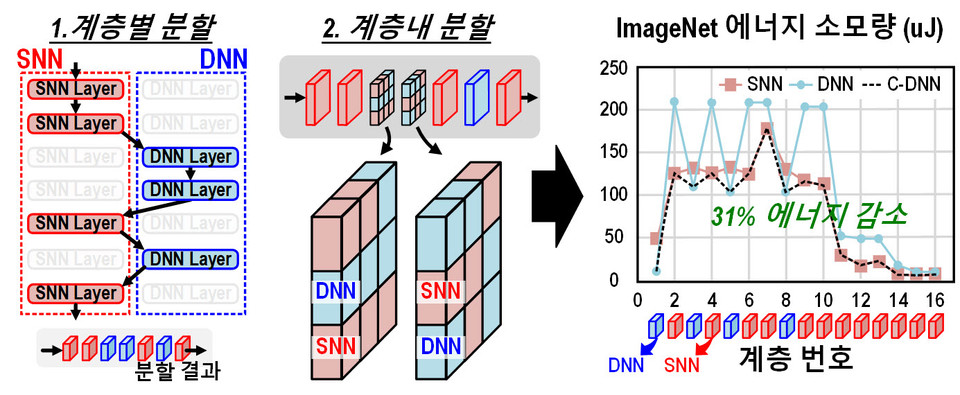
상보형 심층신경망 기술은 작년 2023년 2월에 개최된 국제고체회로설계학회(ISSCC 2023)에서 이번 연구의 제1저자인 김상엽 박사가 발표한 것으로 DNN과 SNN를 혼합하여 사용하며 입력 데이터들을 크기에 따라 서로 다른 신경망에 할당해 전력을 최소화할 수 있는 기술이다.
사람의 뇌가 생각할 것이 많을 때 에너지 소모가 많고 생각할 것이 적을 때 에너지 소모가 적은 것과 마찬가지로, 뇌를 모방한 SNN은 입력값의 크기가 클 때는 전력을 많이 소모하고 입력값의 크기가 작을 때에는 전력을 적게 소모한다. 작년 연구에서는 이러한 특징을 활용해 작은 입력값들만을 SNN에 할당하고 큰 값들은 DNN에 할당해 전력 소모를 최소화 하였다.
이번 연구는 작년의 상보형-심층신경망 기술을 거대 언어 모델에 적용함으로써 초저전력·고성능의 온디바이스 AI가 가능하다는 것을 실제로 입증한 것이며, 그동안 이론적인 연구에만 머물렀던 연구내용을 세계 최초로 인공지능반도체 형태로 구현한 것에 의의가 있다.
특히, 연구팀은 뉴로모픽 컴퓨팅의 실용적인 확장 가능성에 중점을 두고 문장 생성, 번역, 요약 등과 같은 고도의 언어 처리 작업을 성공적으로 수행할 수 있는지를 연구하였으며, 그 과정에서 가장 큰 관건은 뉴로모픽 네트워크에서 높은 정확도를 달성하는 것이었다.
일반적으로 뉴로모픽 시스템은 에너지 효율은 높지만 학습 알고리즘의 한계로 인해 복잡한 작업을 수행할 때 정확도가 떨어지는 경향이 있었으며, 거대 언어 모델과 같이 높은 정밀도와 성능이 요구되는 작업에서 큰 장애 요소로 작용했다. 이러한 문제를 해결하기 위해 연구팀은 독창적인 DNN-to-SNN 등가변환기법을 개발하여 적용하였다.
이는 기존의 DNN 구조를 SNN으로 변환하는 방법의 정확도를 더욱 끌어올리기 위해 스파이크의 발생 문턱값을 정밀 제어하는 방법이다. 이를 통해 연구팀은 SNN의 에너지 효율성을 유지하면서도 DNN 수준의 정확도를 달성할 수 있었다고 밝혔다.
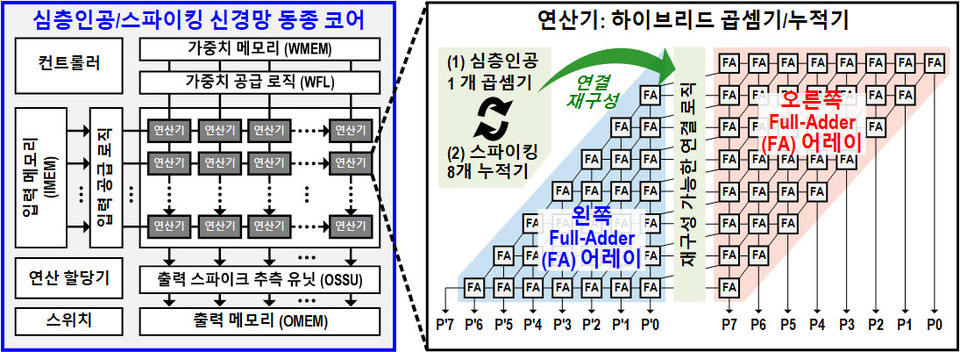
이번 연구를 통해 개발한 AI 반도체용 하드웨어 유닛은 기존 거대 언어 모델 반도체 및 뉴로모픽 컴퓨팅 반도체에 비해 4가지의 특징을 지닌다. DNN과 SNN)를 상호 보완하는 방식으로 융합한 독특한 신경망 아키텍처를 사용함으로써 정확도를 유지하면서도 연산 에너지 소모량을 최적화하였으며, DNN과 SNN을 상보적(Complementary)으로 활용하여 모두 효율적으로 신경망 연산을 처리할 수 있는 인공지능반도체용 통합 코어 구조를 개발하였다.
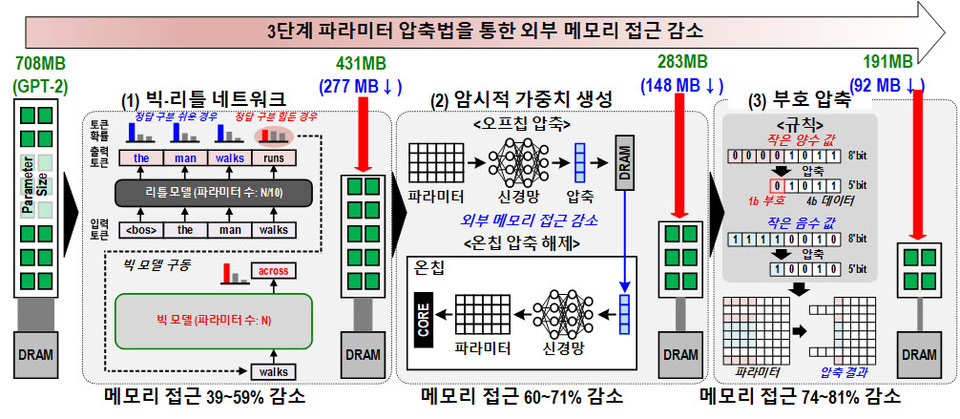
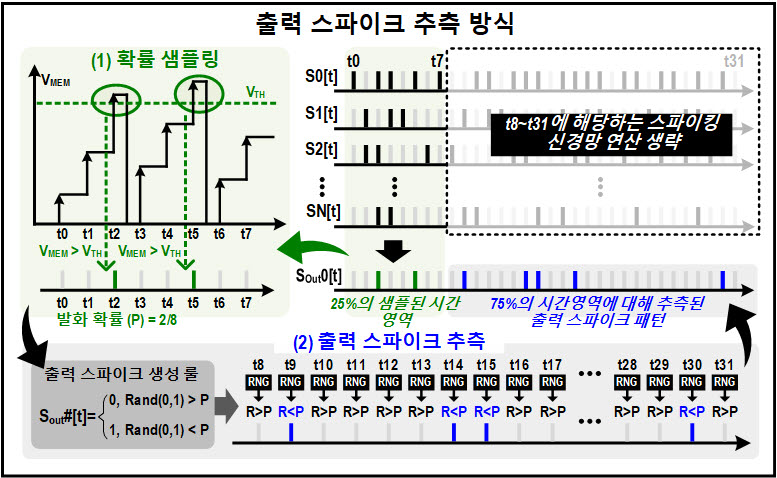
또한, 스파이킹 뉴럴 네트워크 처리에 소모되는 전력을 줄이기 위해 출력 스파이크 추측 유닛을 개발하였으며, LLM의 파라미터를 효과적으로 압축하기 위해 빅-리틀 네트워크(Big-Little Network) 구조와 암시적 가중치 생성기법, 그리고 부호압축까지 총 3가지 기법을 사용하였다.
이를 통해 GPT-2 거대(Large) 모델의 708M개에 달하는 파라미터를 191M개로 줄였으며, 번역을 위해 사용되는 T5 (Text–to-Text Transfer Transformer)모델의 402M개에 달하는 파라미터 역시 동일한 방식을 통해 76M개로 줄일 수 있었다. 이러한 압축을 통해 연구진은 언어 모델의 파라미터를 외부 메모리로부터 불러오는 작업에 소모되는 전력을 약 70% 감소시키는 것에 성공하였다.

그 결과, 상보형-트랜스포머는 전력 소모를 GPU(NVIDIA A100) 대비 625배만큼 줄이면서도 GPT-2 모델을 활용한 언어 생성에는 0.4초의 고속 동작이 가능하며, T5 모델을 활용한 언어 번역에는 0.2초의 고속 동작이 가능하다.
또한, 파라미터 압축에 따른 정확도 하락을 방지하기 위해 경량화 정도에 따른 정확도 하락률을 반복 측정하여 최적화하였다. 이에 언어 생성의 경우 1.2 분기계수(perplexity)만큼 정확도가 감소하였으나, 이는 생성된 문장을 사람이 읽기에 어색함을 느끼지 않을 수준이다.
이러한 특징을 바탕으로 연구팀은 이번 연구 성과는 모바일 장치 등 에너지 제약이 높은 환경에서도 정확하게 거대 언어모델을 구동할 수 있어 온디바이스AI 구현을 위한 최적의 기술이라고 밝혔다.
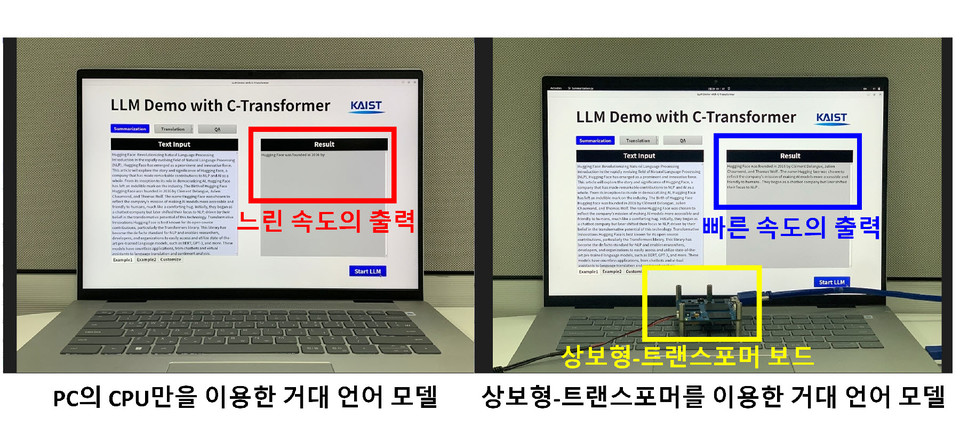
이번 연구는 거대모델의 파라메타 수를 줄이는 데에만 집중된 최근 연구 트렌드와 달리 파라미터 수 감소에 더해 초저전력 처리가 가능한 뉴로모픽 컴퓨팅을 거대언어 모델 처리에 적용하여 에너지 효율을 극대화하였다는 점이 획기적이다.
연구팀은 향후 뉴로모픽 컴퓨팅을 언어 모델에 국한하지 않고 다양한 응용 분야로 연구범위를 확장할 것이며, 상용화에 관련된 문제점들도 파악하여 개선할 예정이라고 밝혔다.

KAIST 유회준 전기및전자공학부 교수는 “이번 연구는 기존 인공지능반도체가 가지고 있던 전력 소모 문제를 해소했을 뿐만 아니라, GPT-2와 같은 실제 거대언어모델 응용을 성공적으로 구동했다는데 큰 의의가 있다.”며, “뉴로모픽 컴퓨팅은 인공지능시대에 필수적인 초저전력·고성능 온디바이스AI의 핵심기술인만큼 앞으로도 관련 연구를 지속할 것”이라고 설명했다.
한편, 김상엽 박사가 제 1저자로 참여한 이번 연구는 지난달 19일부터 23일까지 미 샌프란시스코에서 개최된 국제고체회로설계학회(ISSCC 2024)에서 'C-트랜스포머: 대-소 네트워크와 대형언어모델을 위한 암시적 가중치 생성 기능을 갖춘 2.6~18.1μJ/토큰 동종 DNN-트랜스포머 스파이킹-트랜스포머 프로세서(C-Transformer: A 2.6-18.1μJ/Token Homogeneous DNN-Transformer Spiking-Transformer Processor with Big-Little Network and Implicit Weight Generation for Large Language Models)란 제목(저자: 김상엽, 김상진, 조우영, 김소연, 홍성연, 유회준)으로 발표 및 시연됐다.