크기가 작은 가정용 GPU에서도 대규모 출력 빠르게 수행 가능하며, 최고 성능 동적 메모리 관리자 기술 대비 약 55배, 커널을 2번 실행하는 2단계 기술 대비 약 32배 높은 연산 성능 달성

국내 연구진이 인공지능(AI) 등에 널리 사용되는 그래픽 연산 장치(Graphic Processing Unit, GPU)에서 메모리 크기의 한계로 인해 수 십 만에서 수 백 만 개의 작은 연산들을 동시에 수행하는 초병렬 연산의 결과로 대규모 출력 데이터가 발생할 때 이를 잘 처리하지 못하던 난제를 해결했다.
KAIST(총장 이광형)는 전산학부 김민수 교수 연구팀이 한정된 크기의 메모리를 지닌 GPU를 이용해 수십, 수백 만개 이상의 스레드들로 초병렬 연산을 하면서 수 테라바이트의 큰 출력 데이터를 발생시킬 경우에도 메모리 에러를 발생시키지 않고 해당 출력 데이터를 메인 메모리로 고속으로 전송 및 저장할 수 있는 데이터 처리 기술(일명 INFINEL/인피넬)을 개발했다.
최근 AI의 활용이 급속히 증가하면서 지식 그래프와 같이 정점과 간선으로 이루어진 그래프 구조의 데이터의 구축과 사용도 점점 증가하고 있는데, 그래프 구조의 데이터에 대해 난이도가 높은 초병렬 연산을 수행할 경우 그 출력 결과가 매우 크고, 각 스레드의 출력 크기를 예측하기 어렵다는 문제점이 발생한다.
또한, GPU는 근본적으로 CPU와 달리 메모리 관리 기능이 매우 제한적이기 때문에 예측할 수 없는 대규모의 데이터를 유연하게 관리하기 어렵다는 문제가 있다. 이러한 이유로 지금까지는 GPU를 활용해 ‘삼각형 나열’과 같은 난이도가 높은 그래프 초병렬 연산을 수행할 수 없었다.
이 기술은 구글, 페이스북, 네이버, 카카오와 같은 대기업뿐만 아니라 신생 벤처 기업에서 보유한 그래프 데이터를 기반으로 의사 결정을 내리거나 데이터 분석 및 처리에 활용될 수 있으며 이는 다양한 기업들에게 빠르고 효율적인 솔루션을 제공함으로써 기업과 조직의 경쟁력을 강화할 수 있다.
특히, INFINEL 기술은 GPU 메모리 크기와 상관없이 일관된 성능을 보여주므로, 제한된 비용으로 인해 분석에 어려움을 겪는 기업들에게 적절한 비용으로 더 많은 솔루션을 제공할 수 있다. 뿐만 아니라, 생성형 AI 또는 메타버스에서 GPU 컴퓨팅을 통해 처리하고자 하는 데이터의 크기 및 출력 데이터의 규모가 점점 커짐에 따라, INFINEL 기술을 통해 가속화할 수 있을 것을 기대한다.
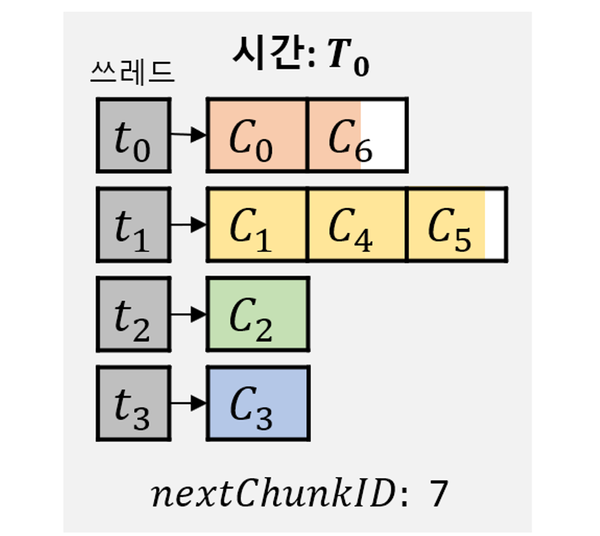
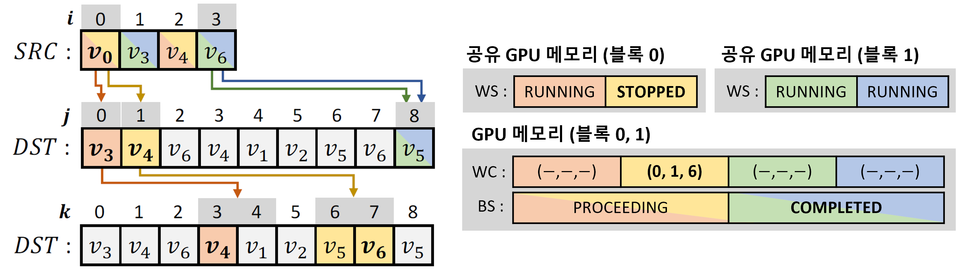
김 교수팀은 이를 근본적으로 해결하는 INFINEL 기술을 개발했다. 해당 기술은 GPU 메모리의 일부 공간을 수백 만개 이상의 청크(chunk)라 불리는 매우 작은 크기의 단위들로 나누고 관리하면서, 초병렬 연산 내용이 담긴 GPU 커널(kernel) 프로그램을 실행하면서 각 스레드가 메모리 충돌 없이 빠르게 자신이 필요한 청크 메모리들을 할당받아 자신의 출력 데이터를 저장할 수 있도록 한다.
또한, GPU 메모리가 가득 차도 무중단 방식으로 초병렬 연산과 결과 출력 및 저장을 지속할 수 있도록 한다. 따라서 이 기술을 사용하면 가정에서 사용하는 메모리 크기가 작은 GPU로도 수 테라 바이트 이상의 출력 데이터가 발생하는 고난이도 연산을 빠르게 수행할 수 있다.
김민수 교수 연구팀은 INFINEL 기술의 성능을 다양한 실험 환경과 데이터 셋을 통해 검증했으며, 종래의 최고 성능 동적 메모리 관리자 기술에 비해 약 55배, 커널을 2번 실행하는 2단계 기술에 비해 약 32배 연산 성능을 향상함을 보였다.
교신저자로 참여한 KAIST 전산학부 김민수 교수는 “생성형 AI나 메타버스 시대에는 GPU 컴퓨팅의 대규모 출력 데이터를 빠르게 처리할 수 있는 기술이 중요해질 것으로 예상되며, INFINEL 기술이 그 일부 역할을 할 수 있을 것”이라고 말했다.
한편, 이번 연구에는 김 교수의 제자인 박성우 박사과정이 제1 저자로, 김 교수가 창업한 그래프 딥테크 기업인 (주)그래파이 소속의 오세연 연구원이 제 2 저자로, 김 교수가 교신 저자로 참여하였으며, 지난 2일부터 6일까지 영국 에딘버러에서 개최된 'PPoPP 2024(병렬 프로그래밍의 원칙과 실제에 관한 ACM SIGPLAN 심포지엄 2024)'에서 '인피넬: 예측할 수 없는 대규모 출력 그래프 쿼리를 위한 효율적인 GPU 기반 처리 방법(INFINEL: An efficient GPU-based processing method for unpredictable large output graph queries-다운)' 란 제목으로 지난 4일(현지시간) 발표됐다.