다른 연구자와 개발자들이 공개적으로 사용 가능한 데이터 세트로 인간의 시각을 정확하게 모델링하는 데 더 가까워지고 심층신경망(DNN)이 인간의 시각 처리 속성을 더 큰 이점으로 얻을 수 있는 기반이 되기를...

'주변 시야(Peripheral vision)' 통해 인간은 비록 디테일은 떨어지더라도 직접 시야에 들어오지 않는 주변 형상을 볼 수 있다. 이 기능은 시야를 넓혀주며, 측면에서 다가오는 차량을 감지하는 등 여러 상황에서 유용하게 사용된다.
그러나 인간과 달리 인공지능(AI)은 '주변 시야'라는 개념이 없다. 컴퓨터 비전 모델에 이 기능을 탑재하면, 접근하는 상황과 위험을 더 효과적으로 감지하거나 인간 운전자처럼 다가오는 물체에 집중할지 여부를 판단하는 데 우선순위 결정에 도움이 될 수 있다.
한 걸음 더 나아가 MIT 연구팀은 인간 주변 시야에서 인공지능이 시뮬레이션하고 사용 가능한 정보를 캡처하기 위해 변환된 이미지를 포함하는 대규모 이미지 데이터 세트 ‘COCO-Periph’를 구축하고 오픈소스로 공개했다. 또한 이 데이터세트로 모델을 학습시키면 시각 주변부의 물체를 감지하는 모델의 능력이 향상되었지만 여전히 사람보다 성능이 떨어졌으나 인간과 달리 객체의 크기나 장면의 시각적 혼란이 AI의 성능에 큰 영향을 미치지 않는다는 사실도 확인했다.

연구팀의 이 연구는 AI가 인간처럼 세상을 더 잘 볼 수 있게 하는 것과 이를 통해 인간의 행동을 밝혀내는 데 도움이 될 수 있다.
이 연구 공동 저자이자 MIT 연구원인 바샤 듀텔(Vasha DuTell) 박사는 "여기에는 근본적인 문제가 있습니다"라며, "우리는 다양한 모델을 테스트했고, 모델을 훈련시켜도 조금씩 나아지기는 했지만 인간과 완전히 같지는 않았습니다“ 라고 말했다. 이어 그는 "그렇다면 이 모델에서 무엇이 부족할까요?"라며, "이것은 이 연구를 통해 연구자들은 인간처럼 세상을 더 잘 볼 수 있는 머신러닝 모델을 구축하는 데 도움이 될 수 있습니다"라며, "이러한 모델은 로봇이나 운전자의 안전을 개선하는 것 외에도 사람들이 보기 쉬운 디스플레이를 개발하는 데 유용하게 사용될 수 있습니다"라고 덧붙였다.
수석 저자 앤 해링턴(Anne Harrington)은 "AI 모델의 주변 시야에 대한 더 깊은 이해는 연구자들이 인간 행동을 더 잘 예측하는 데 도움이 될 수 있으며, 또 주변 시력을 모델링하여 주변부에 표현되는 것의 본질을 제대로 파악할 수 있다면 시각적 장면에서 눈을 움직여 더 많은 정보를 수집하게 만드는 특징을 이해하는 데 도움이 될 수 있습니다"라고 말했다.
MIT 컴퓨터과학 및 인공지능 연구소(CSAIL) 뇌 및 인지과학부의 수석 연구 과학자 루스 로젠홀츠(Ruth Rosenholtz)는 "자동차, 로봇, 사용자 인터페이스 등 사람이 기계와 상호 작용할 때는 그 사람이 무엇을 볼 수 있는지 이해하는 것이 매우 중요합니다"라며, "주변 시야는 이러한 이해에 핵심적인 역할을 합니다"라고 말했다.
보다 정확한 접근 방식을 위해 MIT 연구팀은 인간의 주변 시력을 모델링하는 데 사용되는 기법에서 시작했다. 텍스처 타일링 모델(Texture Tiling Model, TTM)로 알려진 이 방법은 이미지를 변환하여 인간의 시각적 정보 손실을 나타낸다. 연구팀 이미지를 유사하게 변환할 수 있도록 이 모델을 사람이나 AI가 시선을 향할 위치를 미리 알 필요가 없는 보다 유연한 방식으로 수정했다.
텍스처 타일링 모델(참고)이란 초기 시각에서의 표현 모델로, 처음에는 시각적 혼잡을 설명하기 위해 개발됐다. 이 모델은 시각 시스템이 로컬 풀링 영역에서 계산된 풍부한 요약 통계 세트의 관점에서 압축된 표현을 사용한다고 가정한다. 이 표현은 제한된 용량 '병목(bottleneck)'을 통해 가능한 한 많은 정보를 얻기 위한 범용 전략을 시각 시스템에 제공할 수 있다.
연구팀은 이를 통해 인간의 시력 연구와 동일한 방식으로 주변부 시력을 충실하게 모델링할 수 있었다고 설명하고 이 수정된 기술을 사용하여 인간이 주변을 더 멀리 볼 때 발생하는 세부 상황의 손실을 나타내기 위해 특정 영역에서 더 질감이 있는 것처럼 보이는 변환된 이미지의 방대한 데이터 세트를 생성하고 이 데이터 세트를 사용하여 여러 컴퓨터 비전 모델을 훈련하고 물체 감지 작업에서 사람의 능력과 비교했다.
이 과정에서 해링턴은 "정말 놀라웠던 점은 사람들이 주변부에 있는 물체를 얼마나 잘 감지하는가 하는 것이었습니다“라며, ”우리는 적어도 10개의 다른 이미지 세트를 살펴봤는데 너무 쉬웠으며 점점 더 작은 물체를 계속 사용해야 했습니다"라고 말했다.
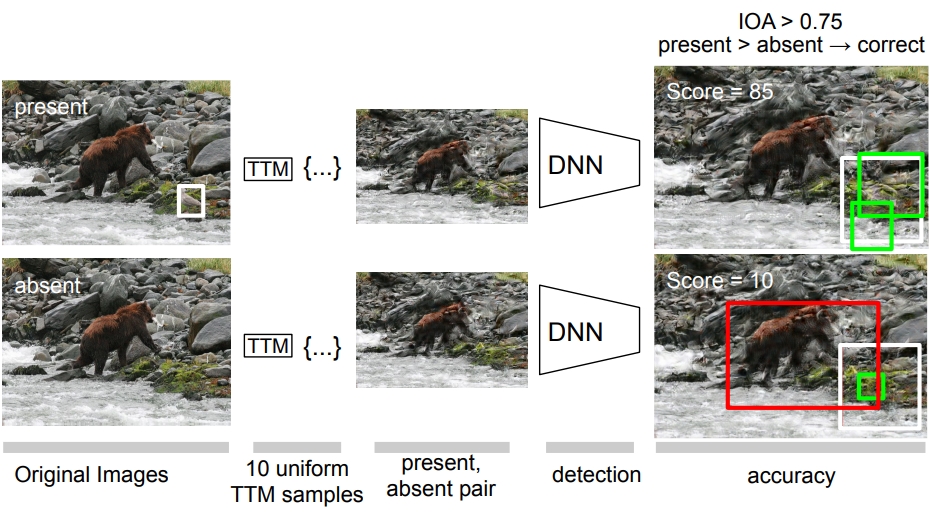
연구팀은 데이터 세트로 처음부터 모델을 훈련하면 물체를 감지하고 인식하는 능력이 향상되어 성능이 가장 크게 향상된다는 사실을 확인했다. 그러나 새로운 작업을 수행할 수 있도록 미리 학습된 모델을 조정하는 프로세스인 데이터 세트로 모델을 미세 조정하면 성능 향상 폭이 더 작았다.
모든 경우에서 기계는 사람만큼 뛰어나지 않았고, 특히 멀리 있는 물체를 감지하는 데 서툴렀으며, 성능 또한 인간과 동일한 패턴을 따르지 않았다. 이에 대해 연구팀은 “이는 모델이 인간이 이러한 탐지 작업을 수행하는 것과 같은 방식으로 컨텍스트를 사용하지 않는다는 것을 시사하는 것으로 모델의 전략은 다를 수 있다"고 밝혔다.
마지막으로 연구팀은 시각적 주변 영역에서 인간의 성과를 예측할 수 있는 모델을 찾는 것을 목표로 이러한 차이를 계속 탐구할 계획이라며, 이를 통해 로봇 등이나 주행 상황에서 운전자가 볼 수 없는 위험에 대해 경고하는 등의 AI 시스템을 가능하게 할 수 있다고 밝혔다.
또한 연구팀은 다른 연구자와 개발자들이 공개적으로 사용 가능한 데이터 세트로 인간의 시각을 정확하게 모델링하는 데 더 가까워지고 심층신경망(Deep Neural Networks, DNN)이 인간의 시각 처리 속성을 모방하고 때로는 더 큰 이점을 얻을 수 있는 기반이 되기를 희망한다고 덧붙였다.
이 연구에 참여하지 않은 스탠포드대학교 심리학과 저스틴 가드너(Justin Gardne) 교수는 "이 연구는 인간의 주변부 시력을 단순히 광수용체(光受容體) 수의 한계로 인한 빈곤한 시력으로만 간주해서는 안 되며, 오히려 실제 작업을 수행하기 위해 최적화된 표현이라는 점을 이해하는데 기여한다는 점에서 중요하다"라고 말했다.
이어 그는 "이 연구는 신경망 모델이 최근 몇 년 동안의 발전에도 불구하고 이와 관련하여 인간의 성능에 필적할 수 없다는 것을 보여준 것으로 이것은 인간 시각의 신경 과학으로부터 학습하기 위한 더 많은 인공지능 연구로 이어질 것"이라며, "연구팀이 인공지능이 다양한 분야에서 인간 주변 시각을 모방하기 위해 이번 공개한 이미지 데이터 세트에 개발자 또는 연구자들은 상당한 도움을 받을 것"이라고 덧붙였다.
한편, 이 연구 결과는 글로벌 최우수 인공지능 학술대회 중 하나로 오는 5월 7일부터 11일까지 오스트리아 비엔나에서 열리는 국제표현학습학회(ICLR 2024)에서 '코코-페리프: 주변부에서 인간과 기계의 인식 간 격차 해소(COCO-Periph: Bridging the Gap Between Human and Machine Perception in the Periphery-다운)'란 제목으로 발표될 예정이며, 사용된 데이터와 코드는 깃허브를 통해 곧 공개(다운)될 예정이다.