초당 3 Tera MAC 이상 성능 구현, 획기적인 IP, 탑재된 장치에 실시간 1080p 장면 분류, 객체 탐색, 픽셀 분할 기능 제공

베리실리콘 홀딩스(VeriSilicon Holdings, 이하 베리실리콘)가 컴퓨터 비전 및 인공 지능을 위한 확장형/프로그램 가능 프로세서 'VIP8000'을 3일(현지시각) 출시했다. VIP8000은 1.5 GMAC/초/mW 보다 효율적인 소비전력과 16FF 공정 기술로 업계에서 가장 작은 실리콘 영역을 갖췄으며, 초당 3 Tera MAC 이상의 성능을 제공한다.
출시된 비반테 VIP8000(Vivante VIP8000)은 멀티스레드 병렬 처리 장치(Parallel Processing Unit), 신경망 장치(Neural Network Unit), 범용 저장 캐시 장치(Universal Storage Cache Unit)로 구성돼 있으며, 카페(Caffe), 텐서플로(TensorFlow) 같은 인기 있는 딥러닝 프레임워크로 생성된 신경망을 직접 불러올 수 있고 신경망은 OpenVX 프레임워크를 사용해 다른 컴퓨터 비전 기능으로 통합할 수 있다.
VIP8000은 현재 인기 있는 신경망 모델 알렉스넷(AlexNet), 구글넷(GoogleNet), ResNet, VGG, Faster-RCNN, 욜로(Yolo), SSD, FCN, 세그넷(SegNet) 등과 레이어<콘볼루션, 디콘볼루션, dilation, FC, 풀링과 언풀링(pooling and unpooling), 다양한 정규화 레이어, 활성함수, 텐서 변형, 요소 단위 연산(elementwise operation) RNN 및 LSTM 기능 등>를 전부 지원하고, 새로운 신경망과 새로운 레이어 유형의 채택을 용이하게 하도록 설계됐다.
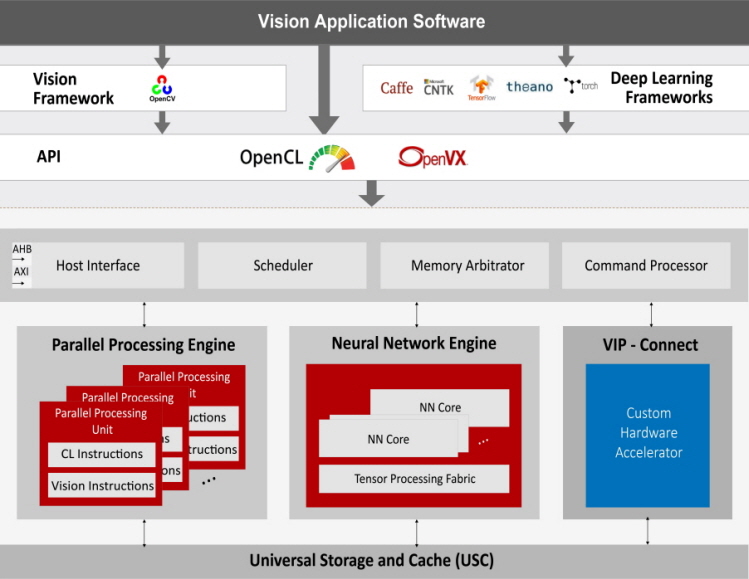
신경망 장치는 고정 소수점 방식의 8비트 정밀도와 부동 소수점 방식의 16비트 정밀도를 모두 지원하고, 최고의 컴퓨팅 효율성과 정확성을 실현하기 위해 혼합 모드 애플리케이션을 지원한다. 비반테 VIP8000의 VIP-커넥트(VIP-Connect™) 인터페이스는 표준 비반테 VIP8000 하드웨어 장치와의 공동 작업을 위해 특정 용도 하드웨어 가속 장치의 신속한 고객 통합을 허용한다.
이 프로세서는 고객의 특정용도 하드웨어 가속 장치를 포함해 하드웨어 장치 전반에 걸쳐 통일된 프로그래밍 모델로 OpenCL 또는 OpenVX에 의해 프로그래밍 된다. 모든 하드웨어 장치는 대역폭을 크게 줄이기 위해 캐시에 있는 공유 데이터로 동시에 작동한다.
탑재된 제품을 다양한 시장 부문에서 보다 잘 적용하기 위해 비반테 VIP8000은 병렬 처리 장치, 신경망 장치, 범용 저장 캐시 장치의 독립적인 확장성을 비롯해 용이한 구성이 가능하도록 되어 있다. 액퀴티(ACUITY™) SDK는 교육 및 완전한 IDE 툴을 제공한다.
베리실리콘의 부사장 겸 최고 전략책임자인 웨이진다이(Wei-Jin Dai)는 “신경망 기술은 빠르게 성장 및 진화하고 있으며, 비반테 VIP8000의 사용 사례는 초기의 감시 카메라 및 자동차 고객 기반을 넘어 점차 확장되고 있다”며
“비반테 VIP8000의 탁월한 PPA(성능, 힘, 영역), 특허 출원 중인 범용 캐시 구성을 통한 획기적인 대역폭 감소, 압축 알고리즘은 탑재된 장치를 클라우드와 공동 작업하는 인공지능(AI) 단말기로 만드는 과정을 가속화하여 최종 사용자가 혁신적인 인공지능을 경험할 수 있게 해준다”고 말했다.
존페디 리서치(JonPeddie Research)의 CEO 존 페디(Jon Peddie)는 “탑재된 장치 내에서 인공지능을 빠르게 성장시키기 위해서는 OpenCL과 OpenVX 같은 업계 표준 API(응용프로그램 인터페이스)를 갖춘 고성능의 강력한 프로그램 가능 엔진이 반드시 필요하다”며 “신경망 혁신과 컴퓨팅 밀도 향상을 통해 효율성을 실현할 수 있다”고 밝혔다. (더 자세한 정보는 웹사이트www.verisilicon.com 참조)