특이한 점은 단어가 아닌 문장을 기본 단위로 학습을 한다. 원문의 정보를 단지 하나의 문맥 벡터로 전달하는 것이다. 문맥 벡터 하나에 문장 전체의 함축된 정보를 모두 담아서 전달하고, Decoder RNN 에서는 단지 하나의 문맥 벡터에서 정보를 뽑아서 번역을 마쳐야 한다.

딥러닝에서 널리 적용되고 있는 어텐션(Attention)은 모델을 더욱 정교하고 우수한 성능을 보여준다. 본고에서는 최근 가장 뛰어난 성능으로 많은 분야에서 활약하고 있는 AI 기술 분야인 어텐션에 대하여 알아 본다.
▷ 워드 엠베딩 (Word Embedding)
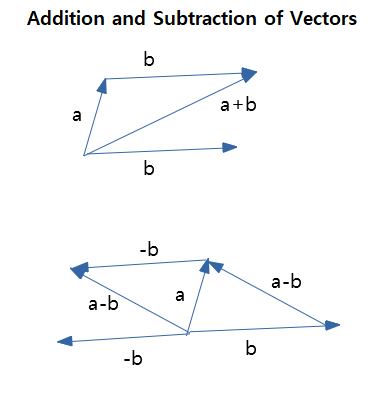
AI의 딥러닝 기술은 기본적으로 벡터 연산으로 이루어져 있다. 벡터는 크기와 방향이 동시에 있는 것이고, 크기와 방향만 유지된다면, 어느 공간의 위치로 옮겨도 같은 벡터인 성질이 있다. 벡터의 마이너스 값은 방향이 반대이고 크기가 같은 벡터를 뜻한다.
서로 다른 벡터간의 뺄셈과 덧셈과 곱셈은 AI 기술의 기반을 이루고 있다.
워드 엠베딩 (word embedding)은 수 많은 문장에서 단어와 단어간의 관계를 word2vec 같은 기술로 표현한 것으로서, 단어간의 벡터 연산을 가능하게 하고, 벡터 연산의 재미있는 결과를 볼 수 있다.
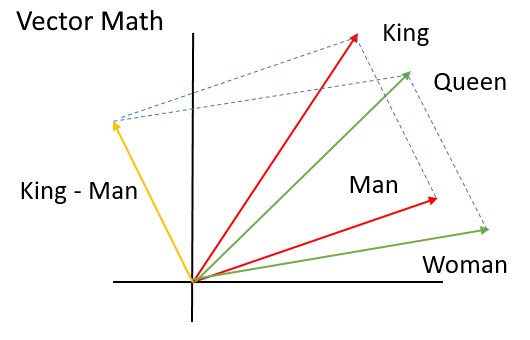
'King - Man + Woman = Queen' 이라는 연산을 수학적인 벡터 연산을 그대로 사용하여 의미있는 답을 찾아낼 수 있게 한다.
이러한 방식은 단어 사전에 있는 단어들이 완전히 독립적인 존재로서 단어가 상호 관련없이 모아놓은 사전과는 다르게, 단어에 실제의 의미를 함께 부여해서 의미있는 답변을 지능적으로 도출할 수 있다.
▷ 문맥 벡터 (Context Vector)
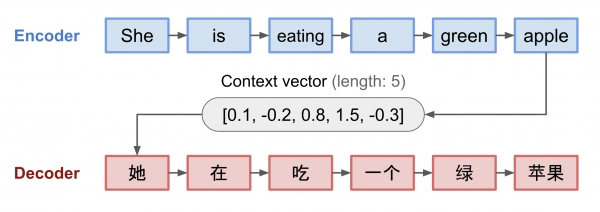
순차적으로 입력되는 신경망인 RNN (순환신경망, Recurrent Neural Networks) 2개를 사용하여, 문장 번역을 할 수 있다. Encoder RNN에서 번역을 위한 원문의 단어를 순차적으로 입력하고 그 결과물로 문맥 벡터 (context vector)를 얻는다.
Decoder RNN에서는 번역을 위한 원문에 대한 정보를 가져와서, 목적으로하는 언어로 번역하는 기능을 하도록 할 수 있다.
여기서, 특이한 점은 단어가 아닌 문장을 기본 단위로 학습을 한다. 원문의 정보를 단지 하나의 문맥 벡터로 전달하는 것이다. 문맥 벡터 하나에 문장 전체의 함축된 정보를 모두 담아서 전달하고, Decoder RNN 에서는 단지 하나의 문맥 벡터에서 정보를 뽑아서 번역을 마쳐야 한다.
고정된 숫자 갯수의 하나의 문맥 벡터만으로 세상의 모든 문장에 대한 정보를 각각 담기에는 한계가 있을 것이다.
▷ 어텐션 (Attention) 개념의 본질

어텐션은 최근의 좋은 성능을 내는 AI에서 자주 도입되는 인기 있는 기반 기술이다. 문맥 벡터의 한계를 넘어서며 매우 좋은 성능을 낼 수 있는 구조이다.
'I love you'를 번역하여 '난 널 사랑해'를 만드는 예를 살펴보자.
문맥 벡터 방식은 영어 원문의 마지막 입력 단어가 입력되어서야 비로서 문맥 벡터 하나를 생성하여 한국어 번역기 (디코더)에 제공되어서 한국어 문장 전체를 생성한다. 그러나 한국어 번역문을 생성할 때, 만들어지는 한국어 각각의 단어는 참고로 하는 영어 원문의 각각의 단어와 의미적으로 밀접한 관계를 맺고 있다.
문맥 벡터를 사용하는 경우에는 한국어 번역의 각각의 단어가 생성될 때, 참고로 하는 정보가 모두 동일한 문맥 벡터 하나만 참고하므로 성능에 한계가 있게 된다.
영어 원문의 마지막 단어까지 입력된 후에나 만들어지는 문맥 벡터 이외에, 영어 원문의 단어가 순서적으로 입력될 때 마다 그 시점에서 문맥 벡터를 하나씩 만든다고 생각하면 어텐션 개념에 빠르게 접근할 수 있다. 즉, 영어 원문의 각 단어가 입력될 때 마다 대응하여 하나씩 문맥 벡터가 짝지워져 있다고 볼 수 있다.
이러한 상황에서 한국어를 생성할 때, 영어 원문의 단어마다 붙어 있는 문맥 벡터 중에서 어느 문맥 벡터의 정보를 이용하여 한국어 단어를 생성할 지 결정하는 것이 어텐션의 본질적인 중요한 사항임을 기억한다면 어텐션 개념에 쉽게 접근할 수 있게 된다.
▷ 어텐션 (Attention)의 예
여러 개의 숫자가 있고 그 중에 2개는 0으로 채워진 경우를 보자.
교육 샘플 예제 : [1,2,3,0,2,7,4,0,4,2] = 6, [1,0,4,7,5,0,3,6,9,4] = 7
이러한 경우에, [2,5,4,7,0,2,3,6,0,3] = ? 의 답은 무엇인가?
교육 샘플 예제가 몇 개 없는 경우에는 규칙을 찾아 내기 어렵지만, 교육 샘플 예제가 매우 많은 경우에는 숨어 있는 규칙을 찾아내어서, 교육 샘플 예제에는 없던 새로운 문제에 대해서 답을 할 수 있게 된다.
숨어 있는 규칙은, 숫자 0이 있는 다음 숫자를 더한 것이 답이다. 그래서, 위의 문제의 답은 '5'가 된다.
이러한 예제의 경우에 입력은 LSTM (Long-Short Term Memory) RNN을 사용하고, 중간에 어텐션 층을 넣고, 출력은 하나의 선형(linear) 노드(node,뉴런)를 넣는 구조로 설계할 수 있다.
많은 교육 샘플 예제로 학습을 시킨 후, 학습에 사용되지 않은 새로운 문제를 내고, 학습 과정에서 어텐션을 하는 정도를 쉽게 볼 수 있는 그림으로 나타내었다.
아래의 그림은 20개의 숫자로 이루어져 있으며, '0'이 무작위로 2개 위치한 경우에 '0' 뒤에 두 숫자를 더한 값을 출력으로하는 것을 2만개 학습하는 과정 중에, 테스트 데이터로 성능 테스트를 하는 것이다.
보기 쉽도록 테스트 데이터는 일부러 테스트를 위해 20개의 숫자로 이루어진 것에서 5번째와 10번째에 강제로 '0'을 넣은 것을 사용한 경우에, 어텐션이 어느 위치 부분을 주의깊게 계산에 이용하는지를 알 수 있다.
쉽게 파악할 수 있도록 아래쪽 흰 막대가 완전한 답이다.
상단의 10개 라인이 테스트하는 것이며, 하단의 10개 라인이 정답의 패턴이다. 붉은 밝은 색이 주의 깊게 (Attention) '0'이 있는 위치를 이용한다는 것을 간파한 것을 나타낸다.

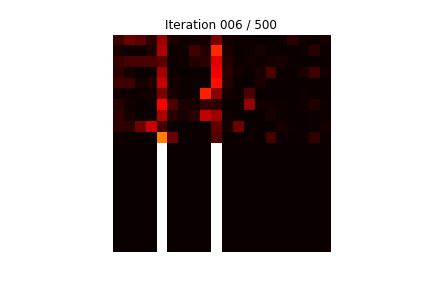
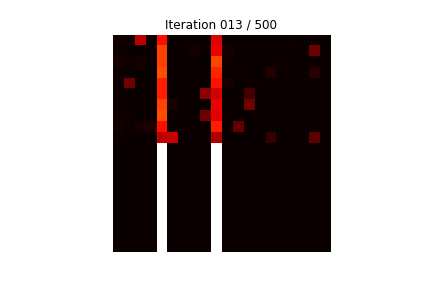

위의 그림에서, 학습을 점점 진행할 수록, 10개의 테스트 (상단 10 라인) 결과, 가로축 5번째와 10번째에 집중하는 것을 볼 수 있는데, 가로축 5번째와 10번째는 일부러 강제로 '0'을 넣어둔 위치이다. '0'이 있는 바로 뒤의 숫자들을 더하여 정답을 내는 것을 볼 수 있다.
이와 같이, 어텐션은 학습 데이터에서 어느 부분에 집중하여 문제의 답을 도출할지 학습 데이터만으로 똑똑하게 알아내어서, 학습시에 보지못한 문제에 대해서도 올바른 답을 도출하는 능력을 가질 수 있게 된다. 이상으로, 정보를 표시하는 벡터와 문맥 벡터와 어텐션에 대해서 알아보았다.