궁극적으로 판단 근거를 아는 기술보다는 성능을 향상하는 기술의 발전에 훨씬 더 많은 투자가 이루어질 것으로 예상한다.

필자, 강신동은 한국산업기술대학 컴퓨터공학과 겸임교수와 서울시 IoT 추진 기술전문위원, 한국건설기술연구원 연구기획위원 등을 역임했으며, 현재 ㈜지능도시 설립자/대표이자 Smart Beam forum 설립 및 운영자로 활동하고 있다.(편집자 주)
본고에서는 딥러닝 AI 분야에서 인공신경망의 최종 결과가 어떤 부분을 보고서 결과를 도출했는지 알기 위한 방법의 일종인 CAM (Class Activation Mapping)에 대해서 알아본다.
▷ 컨볼루션 네트워크(CNN. Convolutional Neural Network)에서 위치정보 소실
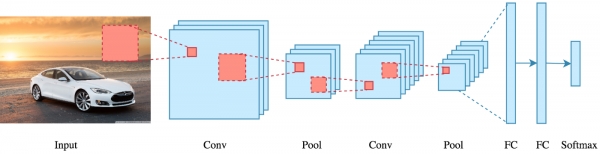
CNN 딥러닝 AI 모델은 뛰어난 성능으로 도약하게 만들어준 대표적인 딥러닝 구조이다.
앞쪽 합성곱(Convolution) 계층에서는 입력의 특성을 추출하고 압축하고 추상화시키는 역할을 하고, 뒷쪽 FC (Fully Connected) 계층은 앞쪽 계층에서 추출된 특성을 분류하는 역할을 한다. 여기서, 앞쪽 부분인 합성곱 계층에서는 한 지점과 그 주위의 상하좌우 지점이 밀접한 상관관계를 이루고 있지만, 뒷쪽 부분인 FC 연결에서는 각 지점의 위치는 전혀 상관이 없다.
앞부분의 합성곱 계층에서 FC 계층으로 연결하기 위한 방법으로 납작하게 하는 (Flatten) 단계를 거친다. 이러한 Flatten 과정에서는 상호간의 관계는 모두 없어지는 과정이고, 완전히 랜덤하게 위치를 일렬로 나열하는 것과 궁극적으로 같은 결과를 가진다. 즉, FC 단계로 넘어가면, 특성을 분류할 수는 있지만, 위치간의 정보는 모두 없어져 버린다.
FC도 패턴인식에 의한 분류 작업을 행하는 것이지만, 그 패턴이라는 것이 원본 이미지의 패턴과는 전혀 상관이 없고, Flatten 단계 후의 FC 의 첫 계층에서 랜덤하게 배치를 했든 순서대로 배치를 했든 관계없이 FC 첫 단계의 패턴을 분류에 사용할 뿐이다.
결국, FC 영역을 거친다는 것은 원본 이미지의 위치와는 전혀 상관없는 정보일 뿐이므로 FC 를 아무리 잘 분석할 수 있다고 하더라도, 원본 이미지의 부분 위치의 상관관계는 알 수 없게 된다.
▷ 클래스 활성화 매핑(Class Activation Mapping. 이하, CAM)
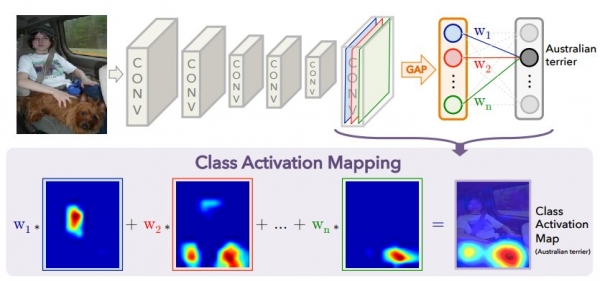
위치 정보를 FC 계층에서 소실하는 CNN 에서 FC 계층을 없애고, 위치 정보를 소실하지 않게 하여 형태학적인 특징을 추출하고 원본 사진의 어느 부분을 보면서 분류를 하는지 사람이 볼 수 있는 방법이 CAM 이다. FC 계층을 없애고 그 부분에 GAP (Global Average Pooling)과 GAP 각 값에 가중치를 가중합 (weighted sum)하여 분류 (classification)을 한다. 가중합에서의 가중치 (weight)는 기계학습의 대상이다.
GAP는 기존에 일반적으로 사용하는 구조인 CNN+FC(Fully Connected layer)에서 분류기인 FC를 없애기 위한 방법 중 하나로 도입됐다.
또한 GAP은 각 채널의 특성(feature)에서 채널별로 하나의 평균값을 정하는 과정이다. 이 단계에서 GMP (Global Max Pooling)을 사용할 수도 있겠지만, 하나의 대표적인 최대값만을 사용하는 GMP보다는 평균값을 사용하여 전반적인 값을 대표하는 GAP를 사용하는 것이 더 좋은 결과를 얻을 수 있다.
합성곱 단계는 본질적으로 필터에 의해서 지역적인 패턴 계산에 의한 결과이고, 여기에 활성화 함수 (activation function)를 통과하고 압축과정 (max pooling) 을 거치더라도 본질적으로 대략적인 위치 정보는 보존된다.
GAP와 가중치를 곱하는 마지막 단계에서, 분류를 위해서 하나의 채널에 대한 GAP 값 1개만을 사용하여 분류가 되도록 가중치 (w)가 정해진다면 그 가중치 이외의 다른 모든 가중치가 0 값이 되어서 다른 채널은 고려하지 않아도 될 것이다. 그러한 경우라면, 마지막 합성곱 계층의 해당 채널 1개의 특성 (feature map)만을 살펴보면 원본 이미지의 대략 어느 부분을 참고하여 최종 결과를 내는지 알 수 있다.
일반적으로는, 단지 하나의 채널 GAP 값만을 사용하는 경우가 아니라, 여러 채널의 GAP 값을 가중치 (w, weight)로 약간씩 참고하여 결과를 내놓을 것이다.
그러한 일반적인 경우를 고려하면, 각각의 채널에 대한 특성 (feature map)을 각 가중치를 적용하여 (곱하여) 더하면 (가중합)을 하면, 모든 채널에 대한 특성을 모두 참고한 종합적인 히트맵 (heat map)을 얻을 수 있으며, 이러한 히드맵을 원본 이미지 크기로 확대한 후, 원본 이미지와 히트맵을 함게 표시하면 원본 이미지의 어느 부분을 참고하여 분류를 행하는지 사람이 눈으로 확인할 수 있는 CAM (Class Activation Map)을 얻을 수 있다.
이러한 노력은 딥러닝의 동작에서 내부의 동작을 사람이 알기는 어렵지만 최대한 조금이라도 판단의 근거를 살펴보려는 사람의 노력으로 CAM 작업은 사진에서 객체를 인식하고 사진의 어느 부분에 물체가 위치하는지를 정하는 방법으로도 사용할 수 있으며, 기존의 위치 인식보다 더 뛰어난 성능을 보이기도 한다.
▷ Grad-CAM (Gradient Class Activation Mapping)
CAM을 얻기 위해서 FC (Fully Connected) 계층을 GAP (Global Average Pooling)을 교체하지 않고, FC를 그대로 둔 상태에서도 앞 부분의 합성곱 (convolution) 부분에서 CAM을 얻을 수 있는 방법으로서 Grad-CAM 방법이 있다. Grad-CAM은 합성곱 계층의 특성 (feature map)에서 각 값의 변화가 최종 분류값에 얼마나 크게 영향을 미치는 것인지의 정도를 구하여 CAM을 얻는 방식이다.
▷ 성능 vs 판단 근거

딥러닝 AI 분야에서 기술의 발전은 판단 결과 성능의 향상을 위한 연구와 더불어, 판단 근거를 밝힐 수 있는 연구가 함께 발전하고 있다. 그러나, 성능을 더 중요하게 볼 것인가 판단 근거를 가진 것을 더 중요하게 볼 것인가는 적용 대상에 따라서 다를 수 있다.
바둑을 두는 알파고에서는 판단의 근거는 인간이 전혀 알 수 없더라도 결과적으로 인간을 압도적으로 이길 수 있는 알파고의 능력은 탁월하게 인정하고 있다. 바둑을 잘 두는 AI 가 목적이지 왜 그 수를 두었는지 알아야만 바둑을 잘 두는 것은 아니기 때문이다. 그러나, 의료 분야인 경우에는 판단 근거가 좀 더 중요성을 더하게 된다. 의료 행위의 결정에 있어서 어느 정도는 사람이 이해할 수 있는 판단을 신뢰할 수 있을 것이기 때문이다.
필자는 궁극적으로 판단 근거를 아는 기술보다는 성능을 향상하는 기술의 발전에 훨씬 더 많은 투자가 이루어질 것으로 예상한다. 바둑을 잘 두는 AI를 개발하는 것과 마찬가지로, 주식 시장에서 돈을 잘 벌 수 있는 AI를 개발하는 것 또한 판단 근거를 아는 것보다는 근본적인 목적을 이루는데 더 많은 투자가 이루어질 것으로 보인다.