이번 MLS가 제한적이지 않은 라이선스와 함께 대규모 다국어 데이터 세트를 제공하고 공통 벤치마크를 설정함으로써 다국어 ASR에서 개방적이고 협력적인 연구를 촉진하고 전 세계의 더 많은 언어에서 음성 인식 시스템을 개선할 것으로

페이스북 AI가 자동 음성인식(Automatic Speech Recognition. 이하, ASR) 연구 선진화를 위해 설계된 대규모 데이터 세트인 다국어 리브리스피치(LibriSpeech. 이하, MLS)를 오픈 소스로 최근 공개했다. MLS는 음성 연구 커뮤니티가 단순히 영어를 넘어 언어로 작업할 수 있도록 설계되어 있어 전 세계 사람들이 광범위한 AI 기반 서비스를 개선함으로써 혜택을 누릴 수 있다.
말뭉치(Corpus) MLS는 8개 언어로 50,000시간 이상의 오디오 세트를 제공한다. 현재 제공되는 언어는 영어, 독일어, 네덜란드어, 프랑스어, 스페인어, 이탈리아어, 포르투갈어 및 폴란드어다. 또한 연구자들이 서로 다른 ASR 시스템을 비교하는 데 도움이 되는 기준선과 함께 언어 모델 훈련 데이터와 사전 학습된 언어 모델도 제공한다. 이 제품은 공용 도메인 오디오북을 활용한다.

특히, MLS는 다양한 스피커를 가진 대규모 데이터 세트를 제공하며, 제한적이지 않은 라이센스로 누구나 출시할 수 있다.
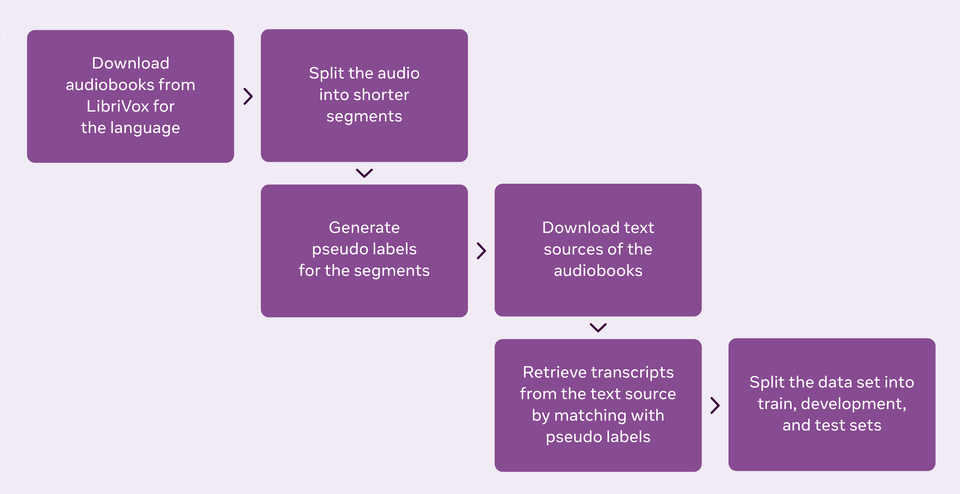
MLS는 활용되는 읽기 음성 데이터 세트로 ASR 벤치마크를 통해 더 큰 규모로 만들고 영어 전용에서 위에서 언급한 7개의 다른 언어로 확장했다. 이를 구현하기 위해 오디오 세그먼트에 가장 적합한 스크립트를 검색하기 위해 오디오를 분할하고 오디오북 텍스트와 정렬했다. 오디오북이 길 수 있기 때문에, 페이스북 AI의 오픈소스 wave2letter@nywhere(다운)를 사용했다.
대부분의 기존 온라인 음성 인식 솔루션은 반복적인 신경망(RNN)만 지원한다. wav2letter@awhere의 경우, 페이스북 AI는 대신 완전히 컨볼루션 음향 모델을 사용하는데, 이것은 LibriSpeech에서 특정 추론 모델과 최첨단 성능에 대한 3배의 처리량 향상한다.
또한 시스템이 생산 규모(저전력 환경에서 서버 CPU 또는 온 디바이스에서)로 실행되기 위해서는 시스템이 계산적으로 효율적인지 확인할 필요가 있다. 연구 환경에서 낮은 잠복성으로 ASR 시스템을 취하는 것은 매우 정확한 계산 효율적 시스템으로 구현과 알고리즘에 대한 사소한 변경을 포함한다.
즉, wav2letter@Anywhere 프레임워크를 사용하여 스트리밍 추론과 정렬을 수행한 것이다.
제한적이거나 감독하지 않는 ASR의 벤치마크인 Libri-Light의 성공에 영감을 받아, 포함된 모든 언어에 대해 제한된 라벨 데이터(10분, 1시간, 10시간)를 가진 서브셋을 제공한다. 이는 자체 감독 및 반 감독 설정과 같이 소량의 레이블링된 데이터를 사용할 수 있는 학습에 적합하다.
언어 모델링 데이터를 준비하기 위해 페이스북 AI는 프로젝트 구텐베르크(Project Gutenberg-다운) 디지털 라이브러리의 공공 도메인을 활용했다. 그리고 개발과 테스트 세트와 겹치는 라이브러리를 신중하게 필터링하고 언어별 텍스트 정규화를 수행하여 언어 모델 코퍼스를 생성했다.
또한 기본 음향 모델을 학습하고 각 언어에 대해 5-그램 언어 모델을 사용하여 디코딩했다. LibriSpeech의 표준 노이즈 테스트 세트와 비교하여 MLS의 영어 하위 집합에 대해 훈련된 모델을 평가하는 동안, LibriSpeech 데이터를 사용하여 학습된 동일한 모델에 비해 단어 오류율이 20% 향상되었다.
공개된 데이터 세트와 벤치마크는 최근 AI가 발전한 주요 원동력으로 MLS는 ASR 시스템의 대규모 교육에 대한 연구를 위한 귀중한 자원을 제공한다. 영어 데이터 세트는 LibriSpeech에 있는 교육 데이터보다 약 47배 더 크다.
영어가 아닌 언어에 대한 데이터 세트와 벤치마크가 있지만, 상대적으로 작거나 다른 장소에 흩어져 있으며, 개방적이고 허용 가능한 라이센스에서는 거의 사용할 수 없다.
페이스북 AI은 이번 MLS가 제한적이지 않은 라이선스와 함께 대규모 다국어 데이터 세트를 제공하고 공통 벤치마크를 설정함으로써 다국어 ASR에서 개방적이고 협력적인 연구를 촉진하고 전 세계의 더 많은 언어에서 음성 인식 시스템을 개선할 것으로 믿는다고 밝혔다.
MLS는 OpenSLR(다운)에서 사용할 수 있으며 다국어 데이터세트(LibriSpeech. MLS- 다운)는 다운로드할 수 있으며, 모든 사전 훈련된 모델과 모델을 학습하고 평가하기 위한 레시피는 깃허브(다운)를 통해 다운로드할 수 있다. 더 자세한 내용은 관련 연구 논문 'MLS : 음성 연구를위한 대규모 다국어 데이터 세트 연구(MLS: A Large-Scale Multilingual Dataset for Speech Research- 다운)'을 참고하면 된다.
관련기사
- [AI 리뷰] 영상으로 인공지능이 로봇 티칭한다!... 페이스북 AI, 오픈 소스로 공개
- [AI 리뷰] 페이스북 AI, 자가지도 학습과 다중 이미지 예측 통한 'COVID-19 악화 예측 AI' 오픈 소스로 공개
- 페이스북 AI, 이미지 분류 위한 새로운 AI 기술 'DeiT' 오픈 소스로 공개
- 페이스북 AI, 인간을 뛰어넘는 포커 실력을 보여주는 AI '레블(ReBeL)' 오픈 소스로 공개
- 페이스북AI, '지식 집약적 언어 작업' 벤치마크... 단일 소스에 11개 데이터 세트 정렬
- [AI 리뷰] 질병 치료 위한 최상의 약물 조합... 혁신적으로 추론하는 인공지능 모델 오픈 소스로 공개!
- 페이스북 AI, 한국어 포함한 전 세계 101개국 언어... 다대다 데이터 세트 '플로레스-101' 오픈 소스로 공개
- [스페셜리포트] 101개국 구어와 문어, 실시간 번역하는 메타AI의 혁신적인 인공지능과 데이터셋 오픈소스로 공개
- [AI 리뷰] 메타 AI, 초거대 인공지능 언어모델 ...1750억개 매개변수의 'OPT-175B' 오픈소스로 공개