‘시각적 음향 매칭‘, '시각적 정보에 기반한 잔향’, ‘비주얼보이스’ 등 세 가지 모델로 물리적 공간의 기하학, 해당 지역의 재료 및 표면, 소리가 나오는 위치의 근접성 등 우리가 오디오를 듣는 방식에 모든 요소를 포함

메타버스의 파티에서 어울리거나 증강현실(AR) 안경을 착용하고 거실에서 홈 무비를 볼 때 음향은 이러한 순간을 경험하는 데 중요한 역할을 한다. 우리는 이와 같은 혼합 현실 및 가상 현실 경험을 위해 노력하고 있으며 인공지능(AI)이 사람들이 몰입하는 설정과 사실적으로 일치하는 음질을 제공하는 핵심이 될 것이라고 믿는다.

이에, 메타 인공지능(Meta AI) 연구팀이 메타 리얼리티 랩(Meta Reality Labs)의 오디오 전문가와 이 연구를 주도한 텍사스 대학교 오스틴(University of Texas at Austin)의 컴퓨터 공학과 크리스틴 그라우만(Kristen Grauman) 교수 연구팀과 비디오에 있는 인간의 말과 소리를 시청각적으로 이해하기 위한 세 가지 새로운 인공지능 모델을 오픈소스로 공개했다.

이 모델은 우리를 더 빠른 속도로 가상에서 현실로 이끌도록 설계되어 있다.
연구팀의 모델은 사람의 외모와 소리를 기반으로 사람의 물리적 환경을 이해하는 것을 기반으로 한다. 예를 들어, 콘서트는 큰 공연장에서 하는 것과 거실에서 하는 것 사이에는 큰 차이가 있다. 그 이유는 물리적 공간의 기하학, 해당 지역의 재료 및 표면, 소리가 나오는 위치의 근접성은 우리가 오디오를 듣는 방식에 모든 요소를 포함하기 때문이다.

연구팀이 AI 커뮤니티와 공유하는 모델은 기존 방법을 능가하는 세 가지 시청각 작업에 중점을 두었다.
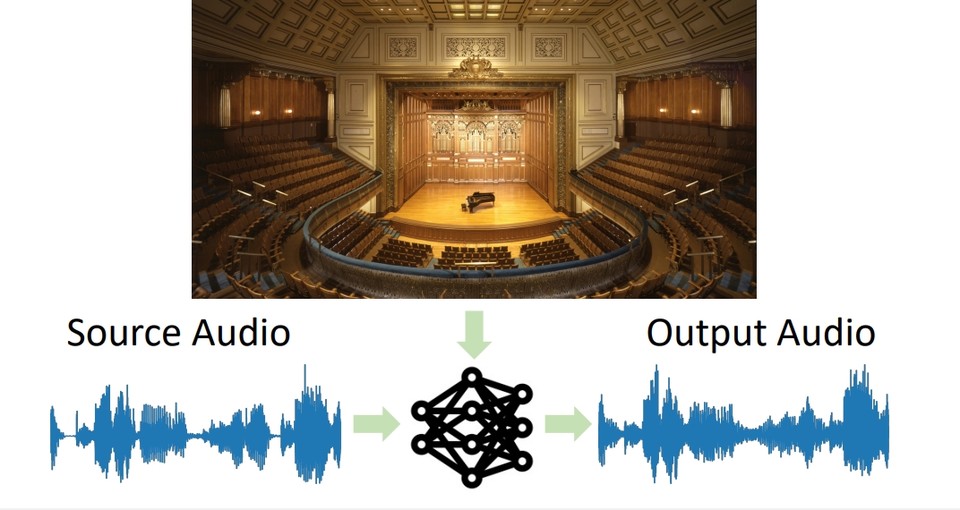
먼저, '시각적 음향 매칭(Visual Acoustic Matching-논문)' 모델의 경우 대상 환경의 이미지와 함께 어디에나 녹음된 오디오 클립을 입력하고 해당 환경에서 녹음된 것처럼 소리가 나도록 클립을 변환할 수 있다.(아래는 CVPR 2022에서 5분 구두 발표 영상)
예를 들어, 모델은 동굴에서 녹음된 음성의 오디오와 함께 레스토랑의 식당 이미지를 촬영하고 그 음성이 사진에 있는 레스토랑에서 녹음된 것처럼 대신 들리도록 할 수 있다.
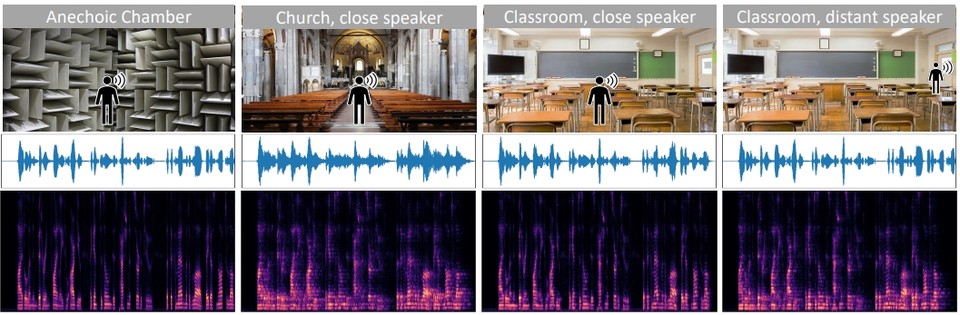
두 번째 모델인 '시각적 정보에 기반한 잔향(Visually-Informed Dereverberation-논문)'은 시각적 음향 매칭의 반대로 관찰된 소리와 공간의 시각적 단서를 사용하여 녹음된 환경에 따라 소리가 만드는 반향인 잔향(메아리)을 제거하는 데 중점을 두었다.(아래는 시뮬레이션된 환경과 실제 세계 모두에서 반향 및 잔향이 감소된 음성의 시청각 영상)
세 번째 모델인 비주얼보이스(VisualVoice-논문/서포트/코드)는 레이블이 지정되지 않은 비디오에서 시각 및 청각 신호를 학습하여 시청각 음성 분리를 달성함으로써 사람들이 새로운 기술을 다중 모드로 습득하는 것과 유사한 방식으로 학습한다.
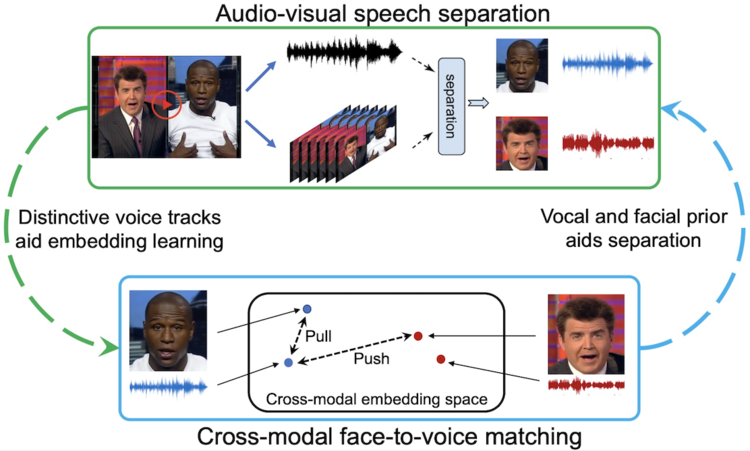
즉, 시각적 및 오디오 신호를 사용하여 음성을 다른 배경 소리와 음성으로부터 분리한다.(아래는 합성 데이터와 웹 비디오 모두에 대한 시각 음향 일치의 시청각 시연영상)
예를 들어, 메타버스에서 전 세계의 동료들과 그룹 회의에 참석할 수 있지만 사람들이 대화를 덜 하고 서로 수다를 떠는 대신 가상 공간을 이동하고 합류함에 따라 잔향과 음향이 그에 따라 조정된다.
이상 세 가지 작업 모두 시청각 인식과 관련하여 Meta AI에서 수행하는 인공지능 연구의 전반적인 분야에서 연결된다. 사람들이 AR 안경을 쓰고 자신의 관점에서 경험한 것과 똑같은 모양과 소리를 내는 홀로그램 메모리를 재현하거나 가상 환경에서 게임을 할 때 그래픽뿐만 아니라 사운드에 몰입하는 느낌을 받을 수 있는 미래를 만드는 것이다.(아래는 AR 및 VR을 위한 메타 AI 기반 음향 합성 소개 영상)