얀 르쿤 비전의 핵심 구성 요소에 기반한 '이미지 조인트 임베딩 예측 아키텍처( I-JEPA)'라는 첫 번째 AI 모델인 이 모델은 픽셀 자체를 비교하는 것이 아니라 이미지의 추상적 표현을 비교하는 외부 세계의 내부 모델을 생성하여 학습..

메타(Meta)가 기존 이미지 생성 AI 모델들을 뛰어넘는 미완성 이미지를 더 정확하게 분석하고 완성할 수 있는 새로운 '인간과 같은(human-like)' 인공지능 모델과 구성 요소를 오픈소스로 13일(현지시간) 공개했다.
이 모델인 I-JEPA는 다른 생성형 AI 모델처럼 주변 픽셀만 보는 것이 아니라 외부 세계에 대한 배경 지식을 사용하여 이미지의 누락된 부분을 채운다.
이 접근 방식은 뉴욕대학교(NYU) 교수이자 메타의 최고 AI 과학자 얀 르쿤(Yann LeCun)이 AI 시스템이 동물과 인간처럼 학습하고 추론할 수 있도록 하겠다는 비전에 주창한 인간과 유사한 추론을 통합한 것으로, 이 모델은 AI 생성 이미지에서 추가 손가락이 있는 손과 같은 공통적인 오류를 방지하는 데 도움이 된다.
인공지능 분야의 대표적인 석학인 얀 르쿤의 비전에 기반한 이 최초의 AI 모델은 보다 인간과 유사한 AI를 지향한다는 것을 특징으로 한다.
지난해 얀 르쿤은 가장 진보된 AI 시스템의 주요 한계를 극복하기 위한 새로운 아키텍처를 제시했다. 그의 비전은 세상이 어떻게 작동하는지에 대한 내부 모델을 학습하여 훨씬 더 빠르게 학습하고, 복잡한 작업을 수행하는 방법을 계획하고, 낯선 상황에 쉽게 적응할 수 있는 머신을 만드는 것이다.
얀 르쿤 비전의 핵심 구성 요소에 기반한 '이미지 조인트 임베딩 예측 아키텍처(Image Joint Embedding Predictive Architecture. 이하, I-JEPA)'라는 첫 번째 AI 모델인 이 모델은 픽셀 자체를 비교하는 것이 아니라 이미지의 추상적 표현을 비교하는 외부 세계의 내부 모델을 생성하여 학습한다.
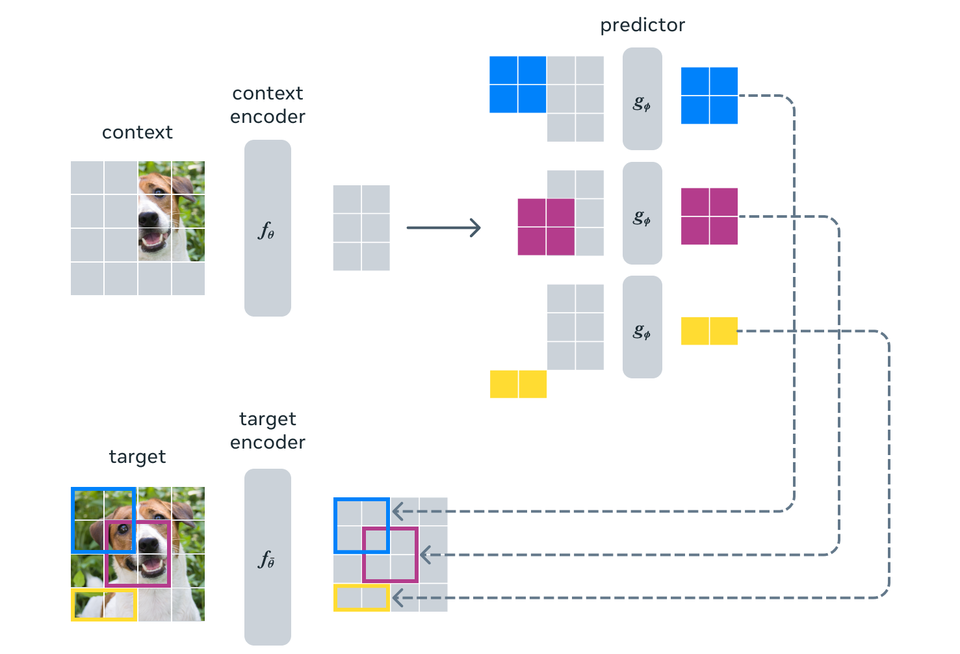
I-JEPA는 여러 컴퓨터 비전 작업에서 강력한 성능을 제공하며, 널리 사용되는 다른 컴퓨터 비전 모델보다 훨씬 더 계산 효율적이다. 또한 I-JEPA로 학습한 표현은 광범위한 미세 조정 없이도 다양한 애플리케이션에 사용할 수 있다.
예를 들어, 16개의 A100 GPU를 사용하여 632M 파라미터의 시각적 변환기 모델을 72시간 이내에 훈련한 결과, 클래스당 12개의 라벨링된 예제만으로 이미지넷(ImageNet)에서 로우샷 분류를 위한 최첨단 성능을 달성했다. 다른 방법은 일반적으로 같은 양의 데이터로 학습할 때 2~10배 더 많은 GPU 시간이 소요되고 오류율도 훨씬 높다.
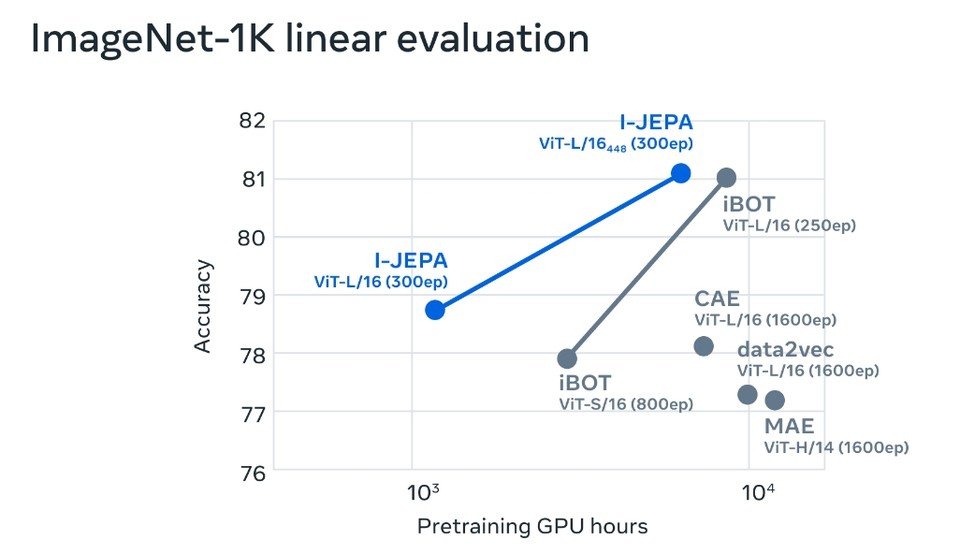
또한 I-JEPA는 시맨틱 작업에서 수작업으로 만든 데이터 증강에 의존하는 이전의 사전 학습 접근 방식과도 경쟁력이 있다. 이러한 방법과 비교하여 I-JEPA는 물체 수 계산 및 깊이 예측과 같은 저수준 비전 작업에서 더 나은 성능을 발휘한다. 즉, 엄격한 귀납적 편향이 덜한 더 간단한 모델을 사용함으로써 I-JEPA는 더 다양한 작업에 적용할 수 있는 것이다.
한편, I-JEPA에 대한 논문 '조인트 임베딩 예측 아키텍처를 사용한 이미지의 자기 지도 학습(Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture-다운)'은 현지시간 18일부터 22일까지 캐나다 밴쿠버에서 열리는 '컴퓨터비전과 패턴인식 학술대회(CVPR 2023)'에서 발표될 예정이며, 학습 코드와 모델 체크포인트는 현재 깃허브를 통해 오픈 소싱(다운)하고 있다.
관련기사
- 메타 '마크 저커버그', "오늘, 우리도 생성 AI 언어 모델 '라마(LLaMA)'를 출시했습니다!"
- 대화를 통해 더 똑똑해지는 인공지능 챗봇...메타 AI, 거의 모든 주제에 말할 수 있는 '블렌더봇 3' 오픈소스로 공개
- 단일 인공지능 모델, 세계 200개 언어 간 고품질 번역 제공!... 메타AI, 매개변수 540억개의 ‘NLLB-200’ 오픈소스로 공개
- 메타AI-텍사스 오스틴大, 메타버스‧AR‧VR 위한 '음향 합성' 인공지능 모델 오픈소스로 공개
- [AI 리뷰] 메타 AI, 메타버스 시대에 강력한 AR 경험 등 '인공지능 음성 인식' 기술의 새로운 도전
- [AI 리뷰] 메타 AI, 초거대 인공지능 언어모델 ...1750억개 매개변수의 'OPT-175B' 오픈소스로 공개
- [스페셜리포트] 101개국 구어와 문어, 실시간 번역하는 메타AI의 혁신적인 인공지능과 데이터셋 오픈소스로 공개
- 사람처럼 보고 듣고 말을 이해하는 '인공지능 어시스턴트' 개발 플랫폼... 메타 AI, 'AV-휴버트' 오픈소스로 공개