공개된 AI 대형언어모델 LLaMA는 단일 시스템이 아니라 매개변수(파라미터)가 70억 개부터 130, 330, 650억 개에 이르기까지 다양한 크기의 모델 4종으로 구분됐으며, 메타의 '연구 사용 사례에 초점을 맞춘 비상업적 라이선스'에 따라 대학, NGO, 산업 연구소 등과 같은 그룹에서 사용할 수 있으며, 이 모델은 용량이 다른 모델의 10분의 1 수준에 불과해 스마트폰 등 다양한 엣지 디바이스에서도 생성 AI 구현할 수 있다.

지난 몇 주 동안 지구촌의 최고의 화두는 오픈 AI의 '챗GPT(ChatGPT)', 구글의 '바드(Bard)', 마이크로소프트의 '빙(Bing)' 등의 언어 생성 AI(Generative AI) 모델에 집중되어 있다. 역시, 이 분야에서 중요한 작업을 계속 이어온 페이스북의 모회사인 메타(Meta)가 24일(한국시간 25일, 새벽 12시 48분) '라마(LLaMA)'라는 새로운 AI 언어 생성 모델을 발표했다.
이날 마크 저커버그(Mark Zuckerberg) 메타 CEO가 페이스북을 통해 "오늘 우리는 연구자들의 연구 발전을 돕기 위해 설계된 새로운 최첨단 AI 대규모 언어 모델인 LLaMA를 출시합니다"라며, "LLM(대형언어모델)은 텍스트 생성, 대화, 서면 자료 요약, 수학 정리 풀이 또는 단백질 구조 예측과 같은 복잡한 작업에서 많은 가능성을 보여 왔습니다. 메타는 이러한 개방형 연구 모델에 전념하고 있으며, 새로운 이 모델을 AI 연구 커뮤니티에 제공할 것입니다"라고 밝혔다.
LLaMA는 챗GPT나 빙과 같지 않다. 누구나 대화할 수 있는 시스템이 아니다. 오히려 메타가 "이 중요하고 빠르게 변화하는 인공지능 분야에서 접근을 민주화"하기 위해 공유하고 있다고 말하는 연구 도구다. 즉, 전문가들이 기존 AI 모델들의 편견과 해악(害惡)에서부터 단순히 정보를 구성하는 경향에 이르기까지 기존의 인공지능 언어 모델의 문제를 해결할 수 있도록 하는 것을 핵심으로 한다.
이 같은 문제에 오픈 AI는 지난 16일(현지시간) '챗GPT(ChatGPT)'가 정치적으로 편향되거나 극단적으로 공격적이거나 서로 다른 방식의 결과 등의 최근 이슈를 인정하고 이를 보완하는 새로운 버전을 개발하고 있으며, 앞으로 몇 달 안에 출시할 것이라고 한다.
또한, 오픈 AI는 최근 제기된 다양한 우려 사항을 인정하고 이를 해결하고자 하는 시스템의 실제 한계를 발견했으며, 시스템과 정책이 함께 작동하여 ChatGPT에서 얻는 결과를 형성하는 방법에 대한 몇 가지 오류도 확인했다고 시인했다.
이에 대한 개선 방안으로▷ChatGPT의 행동이 어떻게 형성되는지 ▷ChatGPT의 기본 동작을 개선하기 위한 방법 ▷더 많은 시스템 사용자 지정을 허용 ▷ 의사 결정에 대해 더 많은 대중의 의견을 얻는 것 등을 꼽았다.
메타가 이날 공개한 AI 대형언어모델 LLaMA는 단일 시스템이 아니라 매개변수(파라미터)가 70억 개부터 130, 330, 650억 개에 이르기까지 다양한 크기의 모델 4종으로 출시됐으며, 메타의 '연구 사용 사례에 초점을 맞춘 비상업적 라이선스'에 따라 대학, 기관, NGO, 산업 연구소 등에서 사용할 수 있다.
특히, 새로운 접근 방식을 테스트하고, 다른 사람의 작업을 검증하고, 새로운 사용 사례를 탐색하는 데 훨씬 적은 컴퓨팅 성능과 리소스가 필요하기 때문에 대규모 언어 모델 공간에서는 LLaMA와 같은 소규모 기초 모델을 학습하는 것이 바람직하다. 이 모델은 용량이 다른 모델의 10분의 1 수준에 불과해 스마트폰 등 다양한 엣지 디바이스에서도 생성 AI 구현할 수 있다.
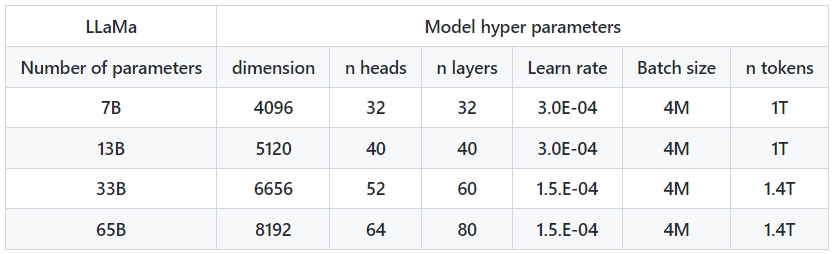
기초 모델은 레이블이 지정되지 않은 대규모 데이터 세트를 기반으로 학습하므로 다양한 작업을 위한 미세 조정에 이상적이며, 더 많은 토큰(단어 조각)으로 훈련된 작은 모델은 특정 잠재적 제품 사용 사례에 맞게 재훈련하고 미세 조정하기가 더 쉽다. 메타는 1조 4천억 개의 토큰으로 LLaMA 65B와 LLaMA 33B를 학습시켰다. 가장 작은 모델인 LLaMA 7B는 1조 개의 토큰으로 학습되었다.
또한 '책임감 있는 AI 관행(Responsible AI practices-보기)'에 대한 접근 방식에 따라 모델을 구축한 방법을 자세히 설명하는 LLaMA 모델 카드도 공유(다운)하고 있다.
다른 대규모 언어 모델과 마찬가지로 LLaMA는 일련의 단어를 입력으로 받아 다음 단어를 예측하여 재귀적(Recursively Generate)으로 텍스트를 생성하는 방식으로 작동한다. 모델을 학습시키기 위해 라틴어와 키릴 문자(Cyrillic Alphabet)를 중심으로 사용자가 가장 많은 20개 언어를 선택했다.
또한, 메타는 "우리는 학계 연구자, 시민 사회, 정책 입안자, 산업계 등 전체 AI 커뮤니티가 협력하여 AI 전반과 특히, 책임감 있는 대규모 언어 모델에 대한 명확한 가이드라인을 개발해야 한다고 믿습니다."라며, "우리는 커뮤니티가 LLaMA를 사용하여 무엇을 배우고 궁극적으로 구축할 수 있을지 기대됩니다."라고 덧붙였다.
아울러, LLaMA 코드를 공유함으로써 대규모 언어 모델에서 이러한 문제를 해결하기 위한 새로운 접근 방식으로 보다 쉽게 테스트할 수 있다.
이날 발표된 모델의 연구 논문(라마: 개방적이고 효율적인 기초 언어 모델/LLaMA: Open and Efficient Foundation Language Models-다운)에서는 모델 편향성과 독성을 평가하는 벤치마크에 대한 일련의 평가 결과를 제공하여 모델의 한계를 보여주고 이 중요한 영역에 대한 추가 연구를 지원한다. 이날 출시한 이 모델 API는 신청(하기)을 통해 다운 받아 학계 연구자, 시민 사회, 정책 입안자, 산업계 등 누구나 사용할 수 있다.
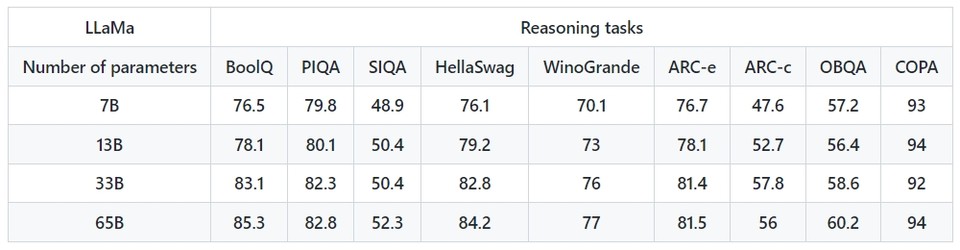
한편, 메타는 연구에서 LLaMA 모델의 두 번째 최신 버전인 LLaMA-13B가 대부분의 벤치마크에서 OpenAI의 GPT-3 모델보다 성능이 우수하고, 가장 큰 LLaMA-65B는 딥마인드의 친치야70B(Chinchilla)와 구글의 PalM540B와 같이 최고의 모델과 경쟁력이 있다고 주장하기도 했다.