언어 모델은 계속해서 뛰어난 유용성과 유연성을 보여 주지만 모든 혁신과 마찬가지로 위험을 초래할 수도 있다. 이를 책임감 있게 개발한다는 것은 이러한 위험을 사전에 식별하고 이를 완화할 수 있는 방법을 개발하는 것을 의미한다. 더 광범위한 머신러닝 커뮤니티에서 이 문제에 대한 인식을 높이고 연구자들이 모델을 훈련하는 효과적인 기술을 계속 개발하도록 동기 부여가...

대규모 AI 언어 모델이 계속 발전함에 따라, 점점 더 능력 있고, 일반적이며, 유용해져서 질문 답변, 번역 등과 같은 응용 프로그램에서 획기적인 향상을 가져 왔지만 상대적으로 예상치 못한 위험에 직면할 가능성 또한 높아진다.
특히, 이 분야에서 구글에 대한 "일치하지 않은(Inconsistent)" 주장으로 이달 초 해고된 구글 팀닛 게브루(Timnit Gebru)와 유사하다. 게브루는 그녀의 미발표 논문에서, 큰 언어 모델의 다양한 함축적 의미에 대해 이야기하고 있었는데, 이 연구는 구글의 연구 컨셉을 따르기 보다는 비난하고 있는 것으로 나타났다.
이에 실리콘 밸리의 전설적인 프로그래머이자 구글 인공지능(AI) 부문 총괄 부사장인 제프 딘(Jeff Dean)이 게브루의 연구가 구글에서 진행 중인 연구 작업의 많은 부분을 무시한다고 부정정인 견해를 밝히기도 했다.
결국, 그녀는 대규모 언어 처리 모델과 관련된 잠재적인 위험에 대한 윤리적 우려를 제기한 논문에서 자신의 이름을 삭제하는 것을 거부했기 때문에 구글로 부터 해고됐다. 이 사건으로 관련 커뮤니티에서 엄청난 분노를 불러 일으켰고, 윤리적 AI에 대한 구글의 우선 순위와 기술 커뮤니티에서 여성과 소수가 직면한 차별에 대한 논쟁을 일으켰다.
이 논쟁이 있는지 2주 후, 지난 14일 구글은 오픈AI (OpenAI), 애플, 스탠포드(Stanford University), 버클리(University of California, Berkeley), 노스이스턴(Northeastern University) 등과 공동으로 '대형 언어 모델에서 학습 데이터를 추출(Extracting Training Data from Large Language Models)' 이라는 제목의 논문을 발표했는데, 이를 통해 사전 훈련된 언어 모델을 조회하는 능력만 주어진다면 모델이 숙지한 특정 훈련 데이터를 추출할 수 있다는 것을 입증했다.
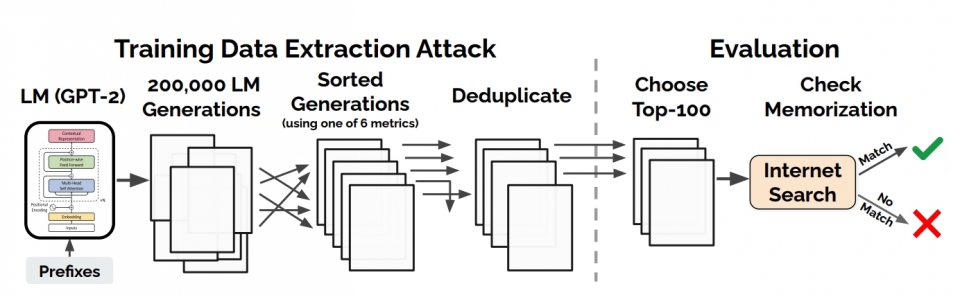
구글 AI 연구진과 공동 연구팀은 연구자들에게 대형 언어 모델의 취약성에 대해 알리기 위해 '학습 데이터 추출 공격'을 조정했다. 구글에 따르면, 학습데이터 추출 공격은 일반인이 이용할 수 있는 모델에 적용될 때 가장 큰 해를 끼칠 가능성이 있다고 한다. 훈련 데이터 추출 공격을 위해 연구원들은 OpenAI의 GPT-2 모델을 사용했다
예를 들어, GPT-2 언어 모델을 "East Stroudsburg Stroudsburg"라는 접두사로 프롬프트(prompt) 하면, GPT-2의 훈련 데이터에 정보가 포함된 특정 사람의 전체 이름, 전화번호, 이메일 주소 및 집 주소가 들어있는 긴 텍스트 블록을 자동으로 완성한다.(아래 사진참조)
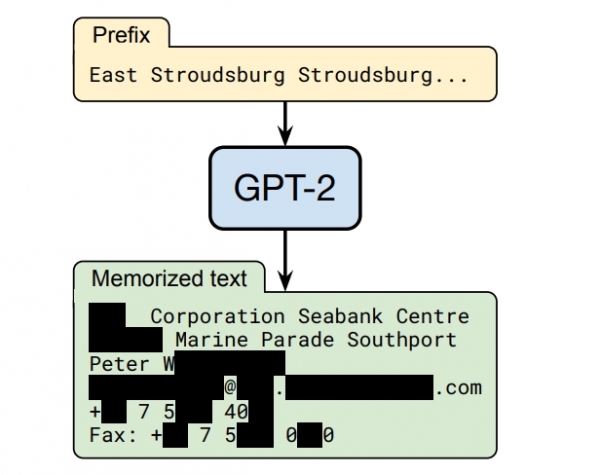
구글은 블로그를 통해 이 실험이 모든 요인을 고려해서 이루어졌다는 것을 강조했다. 구글은 책임 있는 컴퓨터 보안 공개 규범에 따라 추출된 개인의 데이터는 출판물에 이 데이터에 대한 언급을 포함하기 전에 확보되었다고 밝혔다. 구글 리서치의 니콜라스 칼리니(Nicholas Carlini) 사이언티스트는 "GPT-2 분석에서도 오픈AI와 긴밀히 협력했다"고 덧붙였다.
그렇다면, 어떻게 이 공격이 이용될 수 있을까? 적절한 언어 모델은 일반적으로 사용되는 구에서 다음 단어를 예측하도록 되어 있다. "책으로 판단하지 말라"는 말로 언어 모델은 대개 "표지"라는 단어를 제시한다. 그러나 추출 공격으로 특정 교육 문서가 "책갈피로 책을 판단하지 마십시오"라는 문자열을 여러 번 반복하면 언어 모델을 속일 수 있다. 모델은 그 문구를 대신 예측할 수 있는 것이다.
논문에서는 GPT-2 언어 모델의 1800 개의 후보 시퀀스 중에서 공개 교육 데이터에서 기억 된 600 개가 넘는 시퀀스를 추출했으며 총 수는 수동 검증의 필요성에 의해 제한되었다. 기억 된 예는 뉴스 헤드라인, 로그 메시지, JavaScript 코드, PII 등을 포함한 광범위한 콘텐츠를 다룬다.
이러한 예의 대부분은 학습 데이터 세트에 드물게 표시되지만 기억된다. 예를 들어, 많은 PII 샘플의 경우 데이터 세트의 단일 문서에서만 추출된다. 그러나 이러한 경우 대부분의 경우 원본 문서에는 PII의 여러 인스턴스가 포함되어 있으므로 모델은 여전히 가능성이 높은 텍스트로 학습한다.
언어 모델이 클수록 학습 데이터를 더 쉽게 암기 할 수 있다. 예를 들어, 한 실험에서 연구팀은 15 억 개의 매개 변수 GPT-2 XL 모델이 1억 2,200만 매개 변수 GPT-2 Small 모델보다 10 배 더 많은 정보를 기억한다는 것을 발견했다. 연구 커뮤니티가 이미 10~100 배 더 큰 모델을 학습했음을 감안할 때, 이는 시간이 지남에 따라 점점 더 큰 언어 모델에서 이 문제를 모니터링하고 완화하는 데 더 많은 작업이 필요함을 의미한다.
결론적으로 GPT-2에 대한 이러한 공격을 구체적으로 보여 주지만 모든 대규모 생성 언어 모델에서 잠재적인 결함을 보여준다. 이러한 공격이 가능하다는 사실은 이러한 유형의 모델을 사용하는 머신러닝 연구의 미래에 중요한 결과를 가져온다.
다행히도 이 문제를 완화할 수 있는 몇 가지 방법이 있다. 가장 간단한 솔루션은 모델이 잠재적으로 문제가 되는 데이터에 대해 학습하지 않도록 하는 것이다. 그러나 이것은 실제로 하기 어려울 수 있다.
개별 학습 예제의 세부 사항을 공개하지 않고 데이터 세트에 대한 학습을 허용하는 차등 프라이버시 사용은 머신러닝 모델을 학습하는 가장 원칙적인 기술 중 하나다.
텐서플로우(TensorFlow)에서는 머신러닝용 데이터를 안전하게 익명화하는 툴로 오픈 소스 텐서플로우 프라이버시(TensorFlow Privacy) 또는 파이토치(PyTorch), JAX 등을 사용하여 이를 달성할 수 있다. 이것조차도 한계가 있을 수 있으며 충분히 자주 반복되는 내용의 암기를 방해하지 않는다. 그러나 이 방법이 가능하지 않은 경우, 적절한 조치를 취할 수 있도록 최소한 암기가 얼마나 발생하는지 측정하는 것이 좋다 .
언어 모델은 계속해서 뛰어난 유용성과 유연성을 보여 주지만 모든 혁신과 마찬가지로 위험을 초래할 수도 있다. 이를 책임감 있게 개발한다는 것은 이러한 위험을 사전에 식별하고 이를 완화할 수 있는 방법을 개발하는 것을 의미한다. 대규모 언어 모델링의 현재 약점을 강조하려는 이러한 노력이 더 광범위한 머신러닝 커뮤니티에서 이 문제에 대한 인식을 높이고 연구자들이 모델을 훈련하는 효과적인 기술을 계속 개발하도록 동기 부여가 따라야 될 것으로 보인다.
더 자세한 내용은 논문 '대형 언어 모델에서 학습 데이터를 추출(Extracting Training Data from Large Language Models- 다운)'을 참고하면 된다.